专题目录
前言
两个多月前(2024年5月27日),Google 的一份名为 GoogleApi.ContentWarehouse 的 API 文档受到 SEO 圈的关注,由于这份文档的内容和 Google Search 副总裁 Pandu Nayak 在 2023 年美国司法部(DOJ)起诉 Google 的案件中的证词和 Google 的一些专利高度一致,因此其真实性被广泛认可。
后续有媒体称 Google 发言人回应了文档泄露的问题(没有承认、也没有否认):
A Google spokesperson sent us the following statement:
“We would caution against making inaccurate assumptions about Search based on out-of-context, outdated, or incomplete information. We’ve shared extensive information about how Search works and the types of factors that our systems weigh, while also working to protect the integrity of our results from manipulation.”
此前大部分讨论仅限于猜测 API 文档中的各种信号在排名算法中的作用,以及对谷歌是否在排名算法上欺骗了大家。很少人意识到,这篇 2500 页的文档可以作为以往 Google 公开论文的补充,一本叫做《如何构建一个世界级(成功的)搜索引擎》的武功秘籍撕下来的几页。
而偏偏我对这本武功秘籍非常好奇,试图在这几页上再加一些批注,就有了 《Google Search 淘气三千问》这个系列。这个系列会有几篇文章,我不知道,主要看我能想到多少问题。
为什么叫“淘气三千问”这个名字?可以把它看成是一种传承吧,懂的都懂,不懂的也不影响阅读。
为避免误导读者,这个系列所有的回答里,来自公开信息的我都会标注来源,没有标注来源的,你可以认为是 inaccurate assumptions about Search based on out-of-context, outdated, or incomplete information。当未来有了更新的信息,我有可能回到博客来更新这些 assumptions(公众号文章无法更新)。
如果你有新信息可以给我,或者纠正文中的错误,欢迎评论或者到公众号“边际效应”私信,谢谢!
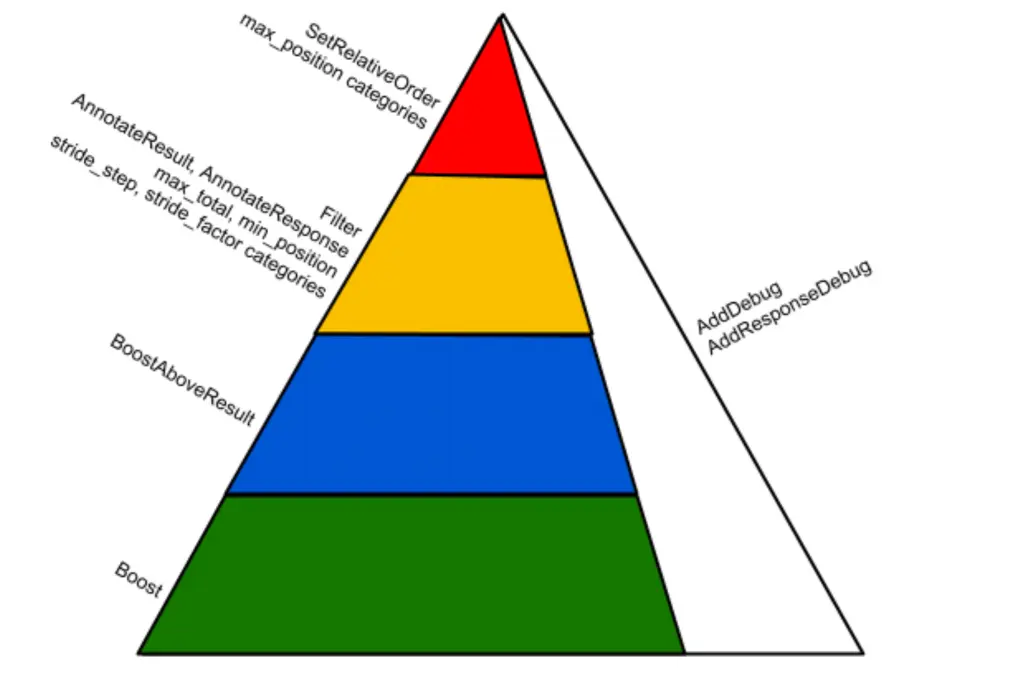
Q1: Google 的索引分了几层(Tier)?依据什么?
Google 在 2012 年的论文《Indexing the World Wide Web: The Journey So Far 》中提到产业实践中大规模索引都是会分成多个桶(tier),一般按照更新频率来分:
The way we have described search indices so far makes a huge assumption: there will be a single unified index of the entire web. If this assumption was to be held, every single time we re-crawled and re-indexed a small set of fast-changing pages, we would have to re-compress every posting list for the web and push out a new web index. Re-compressing the entire index is not only time consuming, it is downright wasteful. Why can we not have multiple indices -- bucketed by rate of refreshing? We can and that is what is standard industry practice. Three commonly used buckets are:
1. The large, rarely-refreshing pages index
2. The small, ever-refreshing pages index
3. The dynamic real-time/news pages index
...
Another feature that can be built into such a multi-tiered index structure is a waterfall approach. Pages discovered in one tier can be passed down to the next tier over time.
在 Google ContentWarehouse API 里有这样一段 :
GoogleApi.ContentWarehouse.V1.Model.PerDocData
* scaledSelectionTierRank (type: integer(), default: nil) - Selection tier rank is a language normalized score ranging from 0-32767 over the serving tier (Base, Zeppelins, Landfills) for this document. This is converted back to fractional position within the index tier by scaled_selection_tier_rank/32767.
可以看到,Google 仍然是把索引分了 3 层,现在我们有了它们的名字,分别是:Base(基础)、Zeppelins(飞艇) 和 Landfills(垃圾填埋场)。在每一层之内,scaledSelectionTierRank 这一归一化分数决定了它所在位置的分位数。分位数最大值是 32767,猜测也许是 Google 在索引存储里只给它留了 15 bits(2^15=32768)。
但从索引分层的名字来看,这三层并不(全)是按照时效性分的,至少第三层,看着是按照文档质量分的。因为你把文档放到“垃圾填埋场”中,大概率因为它的质量较差而不是不再更新。那么 scaledSelectionTierRank 也许就代表了层内的文档质量等级。
网友 avanua 对这三层的命名提供了一个解读,我觉得非常合理,因为我一直困惑第二层为什么叫做 Zeppelins:
我觉得 Tier 命名和质量无关,可能只是用来描绘更新频率:
Zeppelins 在气流中起起伏伏
Base
Landfills 几乎不会再翻动,上下层叠关系是固定的
Q2: Tier 内的 scaledSelectionTierRank 有什么作用?
在 《Indexing the World Wide Web: The Journey So Far》中提到,在倒排拉链中最好按照文档实际的影响力对文档列表进行排序。如果仅仅是这样,那么只需要知道文档 0 比文档 10000 更重要即可,那么额外记录一个打分的目的,其实是可以让这个分数参与排序过程。文档在某个 Query 下的得分,是文档影响力得分乘以文档在 Query-term 下的权重。
Since it made sense to order the posting lists by decreasing term frequency, it makes even more sense to order them by their actual impact. Then all that remains is to multiply each posting value by the respective query term weight, and then rank the documents. Storing pre-computed floating-point document scores is not a good idea, however, since they cannot be compressed as well as integers. Also, unlike repeated frequencies, we can no longer cluster exact scores together. In order to retain compression, the impact scores are quantized instead, storing one of a small number of distinct values in the index.
从上文中有理由认为,scaledSelectionTierRank 就是文中提到的量化以后的文档影响力得分,量化就是将其归一化到 32768 个分档之中。
Q3: Google 搜索系统主要分成几个部分?
通过 API 和其它公开文档,目前我能够分析出来的搜索系统组成部分有以下这些。随着阅读的深入,可能还会有新的部分加进来。
爬虫系统:Trawler
在 Google ContentWarehouse API 中有一系列 API 以 Trawler 为前缀,并且从上下文中看出来 Trawler 是一个实体系统并且有一个研发团队。
GoogleApi.ContentWarehouse.V1.Model.TrawlerCrawlTimes
GoogleApi.ContentWarehouse.V1.Model.TrawlerFetchReplyData
GoogleApi.ContentWarehouse.V1.Model.TrawlerHostBucketData
* TotalCapacityQps (type: number(), default: nil) - The following four fields attempt to make things simpler for clients to estimate available capacity. They are not populated yet as of 2013/08/21. Even after they are populated, they may change. So talk to trawler-dev@ before you use the fields. Total qps for this hostid
去重系统:WebMirror
在 Google ContentWarehouse API 里有这样一段:
GoogleApi.ContentWarehouse.V1.Model.CompositeDocAlternateName
Alternate names are some urls that we would like to associate with documents in addition to canonicals. Sometimes we may want to serve these alternatenames instead of canonicals. Alternames in CompositeDoc should come from WebMirror pipeline.
每个 CompositeDoc 都有一些替代的 URL,这些 URL 来自 WebMirror 流水线,那么 WebMirror 应该是识别重复文档的一套系统。
离线索引构建系统:Segindexer + Alexandria
在 Google ContentWarehouse API 里有这样一段:
GoogleApi.ContentWarehouse.V1.Model.AnchorsAnchor
* sourceType (type: integer(), default: nil) - ... In the docjoins built by the indexing pipeline (Alexandria), ...
所以 Alexandria 应该是建库系统。而 Segindexer 和 Alexandria 曾经并行出现过:
GoogleApi.ContentWarehouse.V1.Model.ClassifierPornClassifierData
* imageBasedDetectionDone (type: boolean(), default: nil) - Records whether the image linker is run already. This is only used for Alexandria but NOT for Segindexer.
考虑到关键的表示原始文档内容的 compositedoc.proto 在 Segindexer 目录下:
GoogleApi.ContentWarehouse.V1.Model.NlpSaftDocument
* bylineDate (type: String.t, default: nil) - Document's byline date, if available: this is the date that will be shown in the snippets in web search results. It is stored as the number of seconds since epoch. See segindexer/compositedoc.proto
从名字和上述信息有理由怀疑 Segindexer 是在 Alexandria 之前,决定了索引分层,或者分 vertical 的一个分类模块。
在线索引服务系统:Mustang 和 TeraGoogle
在 《Indexing the World Wide Web: The Journey So Far》中我们知道,TeraGoogle 是 Google 在 2005 年实现的一套 large disk-based index 服务系统。而在 Google ContentWarehouse API 里有这样一段:
GoogleApi.ContentWarehouse.V1.Model.CompressedQualitySignals
A message containing per doc signals that are compressed and included in Mustang and TeraGoogle.
这里将 Mustang 和 TeraGoogle 并列,有理由认为 Mustang 是 2005 年之后 Google 开发的一套替代或者部分替代 TeraGoogle 的在线索引服务系统。
实时索引服务系统:Hivemind(muppet)
在 Realtime Boost 这篇文档中有一张图,揭示了一个新网页进入索引的过程,其中实时索引的系统叫做 Hivemind。但 Hivemind 应该是个集群名,实际的索引系统方案可能是叫做 muppet。因为在 RealtimeBoost Events - DesignDoc 这篇文档中也提到了一个用 muppet 支持的系统,叫做 ModelT,这是一个索引实时事件的索引系统。
实时索引的建库系统可能与非实时索引不同,叫做 Union。
查询汇聚系统:SuperRoot
在 Google ContentWarehouse API 中多次出现 SuperRoot 这一模块,而在 Jeff Dean 2009 年 WSDM 的 《Challenges in Building Large-Scale Information Retrieval Systems》 分享第 64 页,SuperRoot 被描述为聚合 Web、Images、Local、News、Video、Blogs 和 Books 所有检索子系统的汇聚模块,这个定位也许没有变。
Query 改写模块:QRewrite
在 RealtimeBoost Events - DesignDoc 这篇文档中说:
Currently in production RealtimeBoostServlet runs in QRewrite detects spikes on news documents published that match the SQuery (including syns). It does so by issuing one or two RPCs to Realtime-Hivemind.
The RealtimeBoostResponse containing the Spike is sent down to Superroot in the QRewrite response and it is currently used by a few Search features (such as TopStories) to trigger faster and rank fresher documents for queries that are spiking for a given news event.
所以 QRewrite 是会被 SuperRoot 调用的一个 Query 改写模块,它会将用户实际发起的搜索 Query 改写成 SQuery,S 可能是代表 Superroot。而到真正发起检索时,会进一步转成检索 Query,比如发给 muppet 的 Query 叫做 MQuery。
摘要模块:SnippetBrain
在 Google ContentWarehouse API 里有这样一段:
GoogleApi.ContentWarehouse.V1.Model.MustangReposWwwSnippetsSnippetsRanklabFeatures
* displaySnippet (type: GoogleApi.ContentWarehouse.V1.Model.QualityPreviewRanklabSnippet.t, default: nil) - Snippet features for the final chosen snippet. This field is firstly populated by Muppet, and then overwriten by Superroot if SnippetBrain is triggered.
- 看起来 SnippetBrain 是一个可选的摘要生成模块。
入口服务:GWS
Google Web Server,这个大家都知道,还有 Wikipedia 词条。
Q4: TeraGoogle 是怎样一套系统?
根据论文《Indexing the World Wide Web: The Journey So Far》和专利《US7536408B2: Phrase-based indexing in an information retrieval system》,TeraGoogle 应该有以下几个属性:
- Disk-based Index:索引存储在磁盘上,在需要的时候读入到内存中,而且往往不需要全部读入,针对重要的文档有一些优化;
- Phrase-based Indexing:构建索引的时候不仅仅有 term 索引,还会建设多 term 的短语索引,这样索引库里会有更多的倒排链;
- Document-Partitioned Index:将索引分 Shard 的时候,按照文档进行分片,即同一批文档的所有拉链放在同一个 Shard 上,这样每个 Shard 上有所有的拉链,查询在一个节点内即可完成。在论文中只对比了 Document-Partitioned 和 Term-Partitioned 二者的差异,在 Jeff Dean 2009 年 WSDM 的 《Challenges in Building Large-Scale Information Retrieval Systems》 分享第 17 页确认了 Google 的选择。
Q5: Google 的文档是什么概念?
从 Google ContentWarehouse API 里:
GoogleApi.ContentWarehouse.V1.Model.CompositeDoc
Protocol record used for collecting together all information about a document.
可以看到 CompositeDoc 是在系统里非常重要的概念,它定义了一个文档的所有信息。在它的所有字段中我们发现,url 又是一个可选的字段,这也就是说,文档并不一定需要是一个网页。像 localinfo,看起来就像是一个 POI 信息。也就是说在 Google 的系统里,不一定只有网页索引,可能每个 POI 点、图片、商品也是一种文档,所以它使用 CompositeDoc (复合文档) 而不是 WebPage 作为整个系统里对文档的刻画。