专题目录
- Google Search 淘气三千问:Q1~Q5
- Google Search 淘气三千问: Q6
- Google Search 淘气三千问: Q7~Q9
- Google Search 淘气三千问: Q10~Q12
这个专题停了好久,再更一下。本文内容主要来自对 Google 内部流出的 2018 年文档 Twiddler Quick Start Guide [1] 的总结:
Q10: Google 搜索是怎么对结果进行排序的?
Google 的网页搜索内部叫做 Universal Search,在之前的 Q3 一问中我们提到,SuperRoot 会聚合 Web、Images、Local、News、Video、Blogs 和 Books 等等检索子系统。
每个检索子系统内,会为搜索到的每一条结果打分,负责打分的模块叫做 Ascorer。检索结果聚合到 SuperRoot 后,会先经过 Universal Packer 组件进行一次粗排,或者叫做 ranking,粗排后的结果会经过很多个 Twiddler 进行精排,或者叫做 re-ranking。
Ascorer 打分是 one-result-at-a-time,主要是对 Query-Doc 的匹配情况进行打分;Twiddler 是调整一个子队列(Category)的成员或者顺序;Universal Packer 没有找到资料,我猜测可能是根据 Ascore 和子系统 Quota 分配做一次简单的粗排。
Q11:什么是 Category?
每个检索子系统(Corpus)返回的结果,是一个 Category;Twiddler 也可以根据已有的结果新建 Category。
每个 Category 可以理解成有顺序的一个结果集合,或者叫做一路结果队列。最终的搜索结果,通过将多个 Category 合并而得。
Q12:Google 的 Re-ranking 策略框架?
SuperRoot Twiddler 阶段就是 Google 搜索的 re-ranking 阶段。其中每一个 Twiddler 实际上是一个 C++ 的对象,负责处理一个结果 Category,给出排序建议。
排序建议有以下几种:
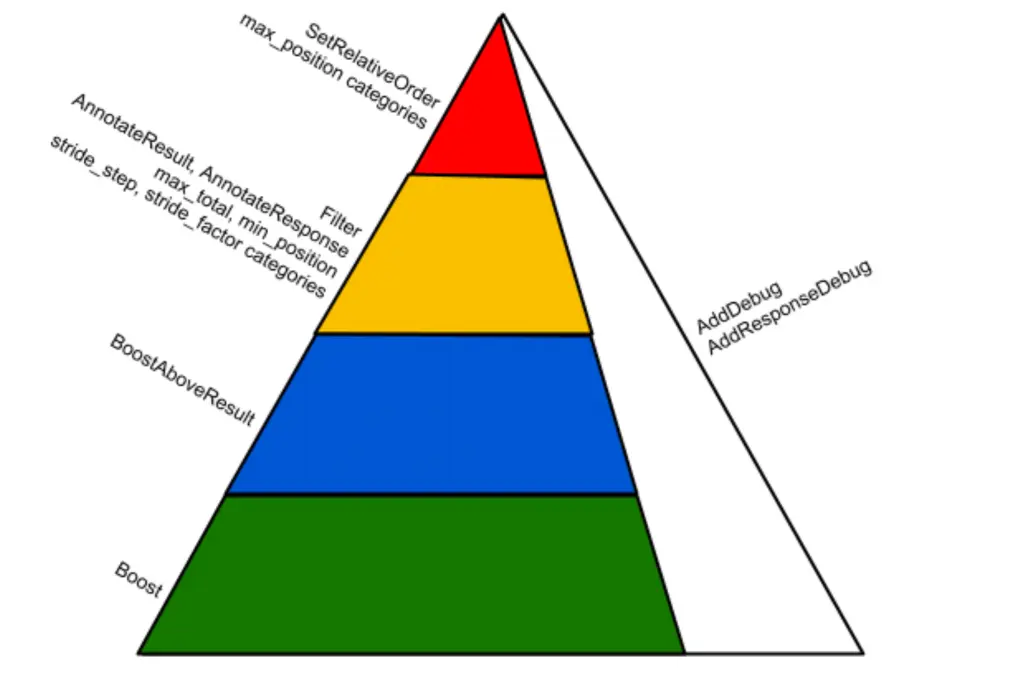
- Boost 和 BoostAboveResult:结果提权/降权,re-ranking 最基本的操作。Boost 是指将结果的分数乘以一个缩放系数 boost,比如 boost = 1.2,代表结果分数要乘以 1.2,就实现了提权的操作;BoostAboveResult 是指将 A 结果的排序提升到 B 结果之上,而其底层的执行方式,是对 B 和 idx(B)-1 位置的结果分数进行插值,确定要对 A 结果得分进行缩放的系数 boost。也就是说 BoostAboveResult 相当于通过比较的方式确定一个 boost,然后再调用 Boost。
- Filter、Hide:结果过滤,用于过滤、反作弊等场景。Filter 是将结果从 Category 中逻辑删除(标记删除),比如某些结果有特征缺失;Hide 是将结果隐藏,比如单站点内容太多,需要用户进一步点击才展示更多结果。
- max_total、min_position、max_position 和 stride:Category 控制/约束。max_total 控制某个 Category 的结果在合并到最终队列时,不超过多少条;min_position/max_position 控制某个 Category 的结果在合并到最终队列时的最高位置和最低位置;stride 控制某个 Category 在合并到最终队列时,最小的间隔是多少。
- NewCategory 和 Categorize:Category 挖掘。NewCategory 创建一个新的 Category;Categorize 将某个其它 Category 的结果,放入这个 Category。
- SetRelativeOrder:类似于 BoostAboveResult,但不通过 boost 缩放系数来控制,而是一定保证将 A 排在 B 前面(如果 B 在结果中出现的话)。
- AnnotateResult 和 AnnotateResponse:为单条结果,或者整个返回包增加一些数据。主要用于提供一些更丰富的展现数据,比如结果的交互数据等。
之所以把这些操作都称为排序建议,是因为 Twiddler 框架的设计有几个原则:
- Isolation:当数百个 Twiddler 都想根据某些特定的信号,对结果进行调整的时候,让 Twiddler 之间存在依赖关系,将会导致无法控制的复杂度。所以每个 Twiddler 的实现都是互相隔离的(运行时不依赖其它 Twiddler 的决策结果)。所以 Twiddler 理论上是可以并行执行的。
- Interaction resolution: 由于每个 Twiddler 的决策都是隔离的,所以它们只能提出约束和建议,即如何去修改排序,而不是给出排序结果。框架负责整体的协调和整合所有排序建议,形成排序结果。
- Provide context:框架需要为每个隔离的 Twiddler 提供只读、安全的上下文访问,让它了解它正在调整的排序结果的上下文环境。
- Ease of experimentation:使 Twiddler 依赖的信号和执行的过程更为简单,这样便于进行在线实验。
Twiddler re-ranking 过程也分成了两阶段:predoc 和 lazy 阶段。
predoc 阶段的 Twiddler 拿到的结果数据更少,被称为 thin result (精简结果)。在 predoc Twiddler 都执行完之后,框架会对结果进行重排序,然后为靠前的结果通过 RPC 补充更多的信号和数据。然后 lazy 阶段的 Twiddler 再对这些结果进行二次排序,形成最终的结果队列。
下图展示的是不同类型 Twiddler 的优先级(也是打包执行顺序):
[1] https://aibrt.org/downloads/GOOGLE_2018-Twiddler_Quick_Start_Guide-Superroot.pdf