上文讲到,FP8 模型之所以无法 TP32 运行,主要因为 DeepSeek R1/V3 模型保存的参数是 FP8 128x128 量化的。Attention 还好,128 个头做 TP16 或者 TP32 都没问题,问题主要出在专家的计算上。
前三层 MLP 的 intermediate_size 是 18432,18432 做 TP16 是 1152,相当于 9 个 128。但如果做了 TP32,就是 4.5 个 128,这会导致参数无法切分在 128 边界上,无法支持按 128 block 量化。路由专家也类似,moe_intermediate_size 做 TP32 相当于 0.5 个 128。
缩小 DeepSeek-R1/V3 的量化块到 64x64
如果想支持 TP32,一个很显然的路径就是把量化方式改成按 64x64 分块量化。本来这是一个比较复杂的操作,但我想了一个取巧的办法:直接把 128x128 的缩放系数,复制到 4 份。
为了方便理解这个方案,我画了一张图。假设我们有一个 4x8 的 INT32 矩阵,按照 4x4 block 量化到 INT8,它会分成 1x2 个 4x4 的块,每块一个缩放系数,那就是 1x2 个缩放系数。如下图所示,第一个块的缩放系数是 7.3465,它是通过第一个块里的最大绝对值 |-933|/127 得到的,同理第二个缩放系数来自 974/127。
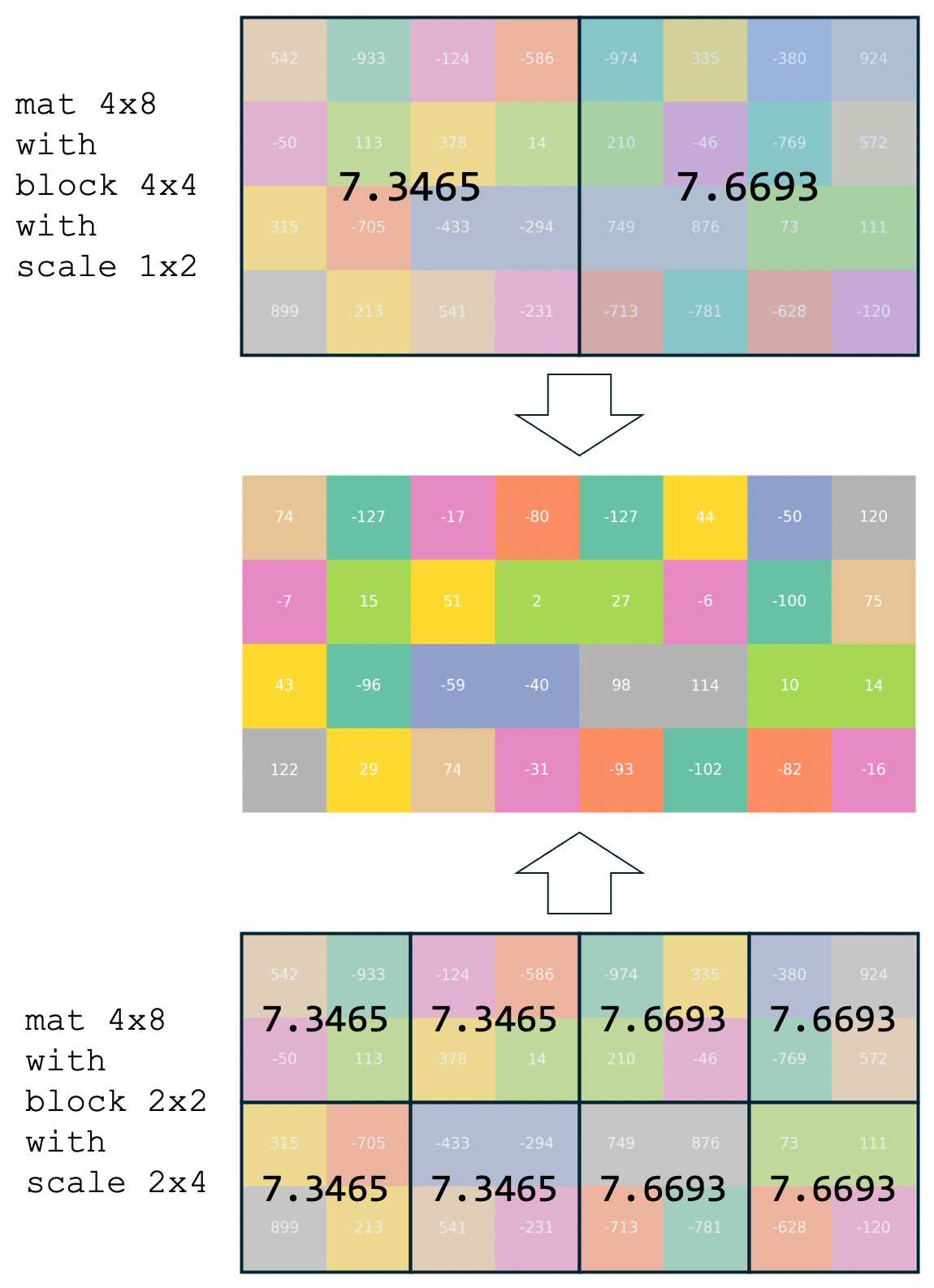
那如果我想将它的量化 block 缩小到 2x2,理论上我应该计算每个 2x2 block 的最大绝对值,然后 /127 得到缩放系数,这样精度损失最小。可是我嫌麻烦,偷个懒,我直接把 4x4 的缩放系数复制 4 份,虽然精度有损失,但好处是在计算上与 4x4 的量化结果完全一致。换句话说,就是原汁原味,纯血参数。
将这个逻辑迁移到 DeepSeek FP8 量化的 128x128 block 缩小到 64x64,原理是一样的,也是将 scale 参数矩阵进行 2x2 等值扩充。通过非常简单的参数处理,就能够实现将 DeepSeek 原始模型转成 64x64 的分块量化,然后就可以用 SGLang 加载运行了。
运行方法
我们以昨天发布的 DeepSeek-V3-0324 为例,逐步说明如何使用这种方法在 L40S 和 L20 上运行 FP8 满血+纯血版的 DeepSeek-V3-0324,不需要等待美团再发布 INT8 版本。
假设你已经下载好了模型,在 /workspace/DeepSeek-V3-0324/。那你需要先下载我的开发分支,并通过源代码安装它(如果遇到困难,建议你在 SGLang 的开发 Docker 中执行它):
git clone -b l40s-dsfp8 https://github.com/solrex/sglang.git
cd sglang
pip install -e "python[all]" --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer-python
然后用下面这个脚本,将 128x128 量化的 DeepSeek-V3-0324,转换到 64x64 量化的 DeepSeek-V3-0324-Block64x64:
python3 scripts/resize_block_size.py /workspace/DeepSeek-V3-0324/
当你在 4 台(或 8 台)机器上都完成了 SGLang 安装和参数拷贝后,就可以用下面的命令来启动 SGLang 服务了。注意替换 MASTER_IP、mlx5_? 和 TCP_IFACE 到正确的值。
# MASTER_IP: 主节点 IP
# TCP_IFACE: 主网卡接口名,可通过 ifconfig 获取
# 主节点
NCCL_DEBUG=INFO NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_? NCCL_SOCKET_IFNAME=TCP_IFACE GLOO_SOCKET_IFNAME=TCP_IFACE python3 -m sglang.launch_server --model /workspace/DeepSeek-V3-0324-Block64x64/ --tp 32 --dist-init-addr MASTER_IP:5000 --nnodes 4 --node-rank 0 --trust-remote --enable-torch-compile --torch-compile-max-bs 32 --cuda-graph-max-bs 32 --host 0.0.0.0 --port 8000
# 从节点 1
NCCL_DEBUG=INFO NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_? NCCL_SOCKET_IFNAME=TCP_IFACE GLOO_SOCKET_IFNAME=TCP_IFACE python3 -m sglang.launch_server --model /workspace/DeepSeek-V3-0324-Block64x64/ --tp 32 --dist-init-addr MASTER_IP:5000 --nnodes 4 --node-rank 1 --trust-remote --enable-torch-compile --torch-compile-max-bs 32 --cuda-graph-max-bs 32
# 从节点 2
NCCL_DEBUG=INFO NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_? NCCL_SOCKET_IFNAME=TCP_IFACE GLOO_SOCKET_IFNAME=TCP_IFACE python3 -m sglang.launch_server --model /workspace/DeepSeek-V3-0324-Block64x64/ --tp 32 --dist-init-addr MASTER_IP:5000 --nnodes 4 --node-rank 2 --trust-remote --enable-torch-compile --torch-compile-max-bs 32 --cuda-graph-max-bs 32
# 从节点 3
NCCL_DEBUG=INFO NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_? NCCL_SOCKET_IFNAME=TCP网卡 GLOO_SOCKET_IFNAME=TCP网卡 python3 -m sglang.launch_server --model /workspace/DeepSeek-V3-0324-Block64x64/ --tp 32 --dist-init-addr MASTER_IP:5000 --nnodes 4 --node-rank 3 --trust-remote --enable-torch-compile --torch-compile-max-bs 32 --cuda-graph-max-bs 32
性能
在 MASTER 节点使用下面的命令进行性能测试(需要先下载测试数据集 ShareGPT_Vicuna_unfiltered/ShareGPT_V3_unfiltered_cleaned_split.json),输入固定 200,输出固定 200,并发 128,测试两轮。
python3 -m sglang.bench_serving --backend sglang-oai --dataset-path /workspace/ShareGPT_Vicuna_unfiltered/ShareGPT_V3_unfiltered_cleaned_split.json --dataset-name random --random-range-ratio 1 --random-input-len 200 --random-output-len 200 --request-rate 128 --num-prompt 256 --max-concurrency 128 --host localhost --port 8000
我测试的性能指标是:
============ Serving Benchmark Result ============
Backend: sglang-oai
Traffic request rate: 128.0
Max reqeuest concurrency: 128
Successful requests: 256
Benchmark duration (s): 98.63
Total input tokens: 51200
Total generated tokens: 51200
Total generated tokens (retokenized): 50971
Request throughput (req/s): 2.60
Input token throughput (tok/s): 519.11
Output token throughput (tok/s): 519.11
Total token throughput (tok/s): 1038.22
Concurrency: 127.26
----------------End-to-End Latency----------------
Mean E2E Latency (ms): 49032.00
Median E2E Latency (ms): 49199.08
---------------Time to First Token----------------
Mean TTFT (ms): 8294.87
Median TTFT (ms): 8306.07
P99 TTFT (ms): 15599.09
---------------Inter-Token Latency----------------
Mean ITL (ms): 205.47
Median ITL (ms): 183.05
P95 ITL (ms): 187.48
P99 ITL (ms): 243.63
Max ITL (ms): 11274.90
==================================================
对照上一篇博客《刷新 32 张 L40S 运行 DeepSeek-R1-INT8 的性能数据》,看起来 FP8 Block 量化的性能比 INT8 Channel 量化的性能要差一些。
代码改动
这次的代码改动不大,主要是参数转换脚本,和一些针对 64x64 的 tunning,以及 warning 的修复。整理好后我会提个 PR 给 SGLang,但这次我不确定这个 PR 是否会被接受,感兴趣的同学可以直接看这个 commit:https://github.com/solrex/sglang/commit/03d34078d8d65983aabc0386391743cc43f535ed or https://github.com/sgl-project/sglang/pull/4860
地震
正当我写到这的时候,忽然手机通知地震了。生平第一次收到,记录一下。我完全没震感,但是有朋友感觉到了。