File "/sgl-workspace/sglang/python/sglang/srt/layers/attention/triton_ops/extend_attention.py", line 356, in extend_attention_fwd _fwd_kernel[grid]( ... File "/usr/local/lib/python3.10/dist-packages/triton/compiler/compiler.py", line 374, in _init_handles raise OutOfResources(self.metadata.shared, max_shared, "shared memory") triton.runtime.errors.OutOfResources: out of resource: shared memory, Required: 102400, Hardware limit: 101376. Reducing block sizes or `num_stages` may help.
Using default MoE config. Performance might be sub-optimal! Config file not found at /usr/local/lib/python3.10/site-packages/sglang/srt/layers/moe/fused_moe_triton/configs/E=256,N=64,device_name=NVIDIA_L40S,dtype=int8_w8a8.json
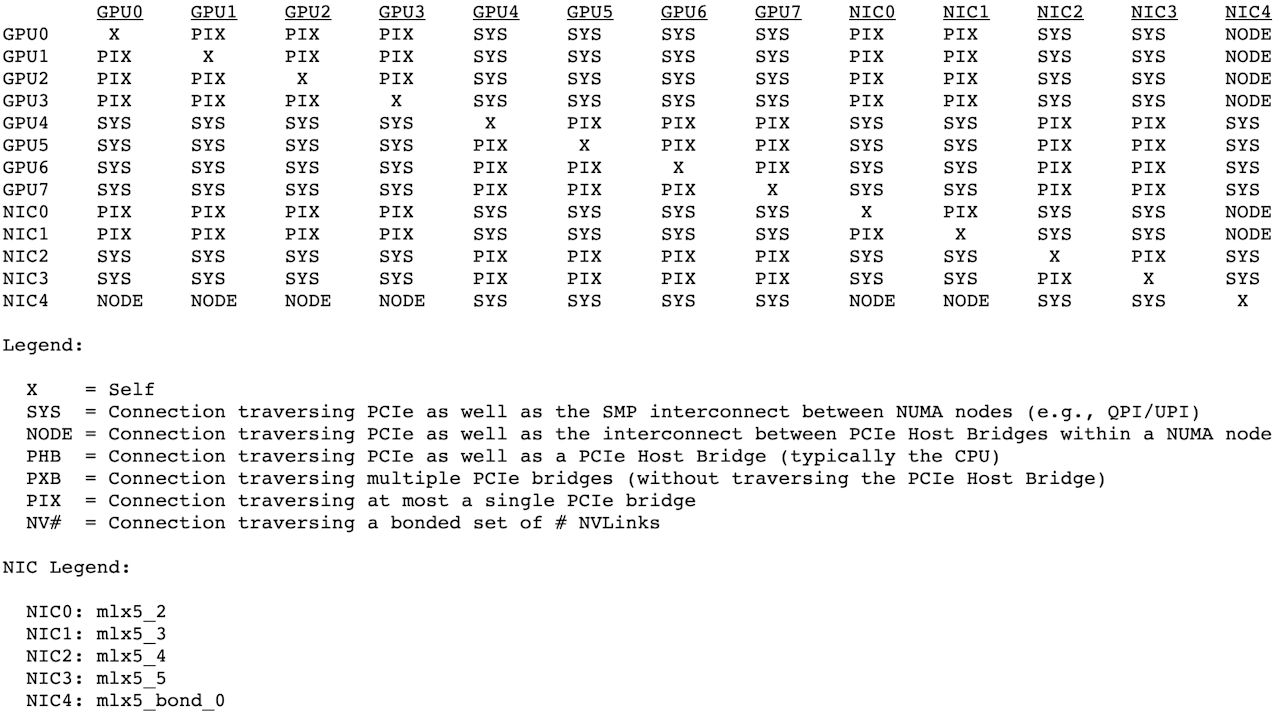
我也实在算不出来这玩意儿的互联带宽。逻辑上来说,这大概相当于用 4 PCIE 4.0 GPU + 2 RDMA 网卡的性能,所以也许这个 4 x 8卡,实际上相当于 8 x 4卡。以下性能评测结果供参考。
下面是加载时的显存使用情况:
[TP0] Load weight end. type=DeepseekV3ForCausalLM, dtype=torch.bfloat16, avail mem=22.43 GB, mem usage=21.27 GB. [TP0] Memory pool end. avail mem=7.95 GB [TP0] Capture cuda graph begin. This can take up to several minutes. avail mem=7.92 GB [TP0] Capture cuda graph end. Time elapsed: 411.41 s. avail mem=5.89 GB. mem usage=2.02 GB. [TP0] max_total_num_tokens=201723, chunked_prefill_size=8192, max_prefill_tokens=16384, max_running_requests=2049, context_len=163840
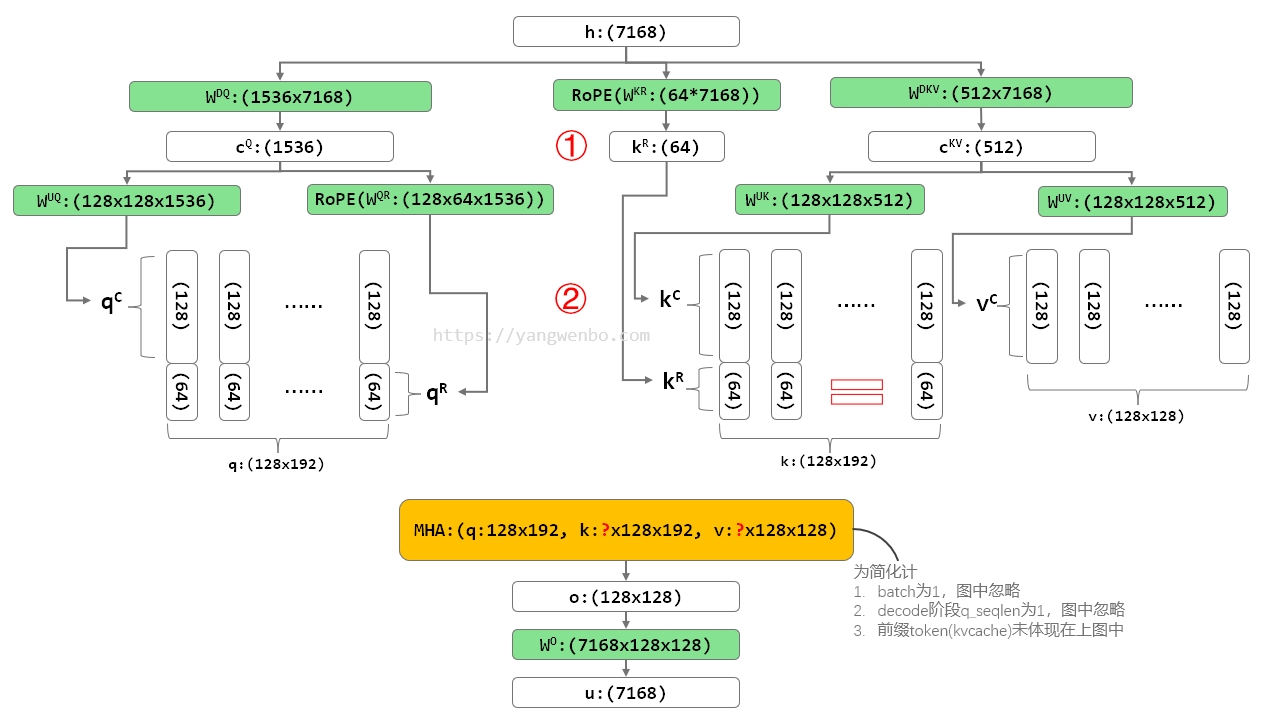
在 Naive 实现中,512 维的 Latent KV cKV 被映射回对应 128 个 head,每个 head 128 维的 K kC 和 V vC,然后再拼接上位置向量 kR ,最终形成标准的 q、k、v,输入到标准的 Multi Head Attention 进行 Attetion 计算。与其他常见模型中 MHA 的唯一不同,可能是 head dim 192 不是 2 的 n 次方。
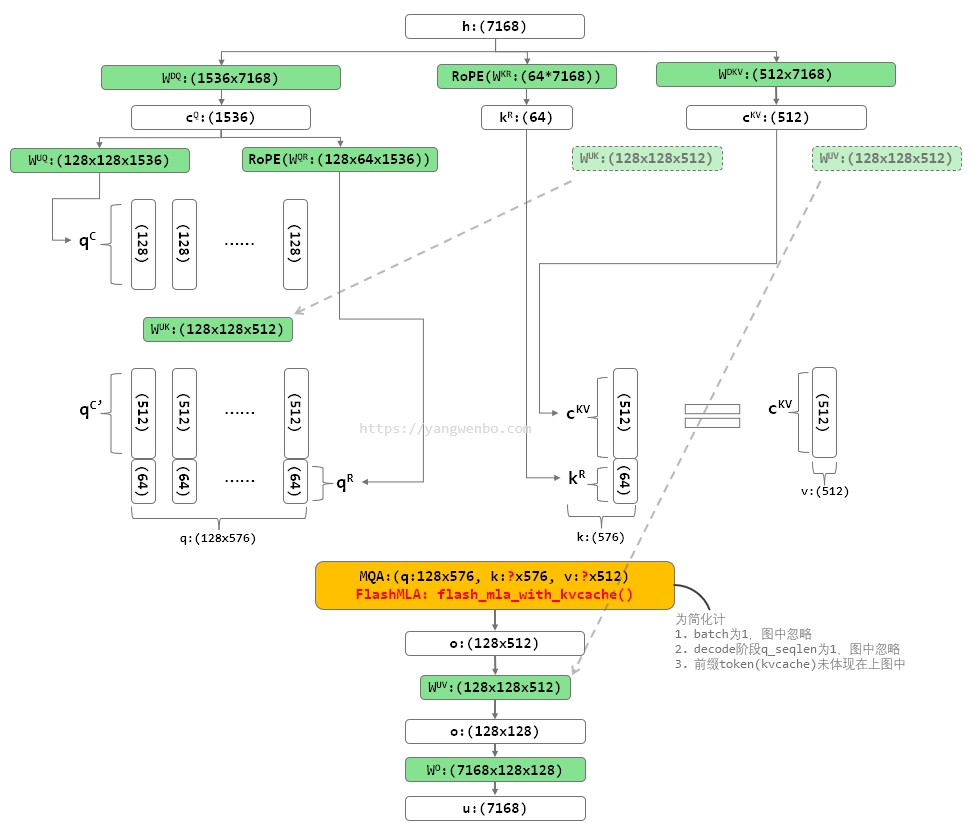
Fortunately, due to the associative law of matrix multiplication, we can absorb WUK into WUQ, and WUV into WO. Therefore, we do not need to compute keys and values out for each query. Through this optimization, we avoid the computational overhead for recomputing kCt and vCt during inference.
与图 3 相比,可以看到输入给 Attention 的 q、k、v 形状发生了明显的变化。q 的形状由 128x192 变化成了 128x576,k 的形状由 128x192 变化成了 576,v 的形状由 128x128 变化成了 512。这样一来,原来的 ② KV 就不存在了,新的计算过程中只剩下 ① Latent KV 了。而且实际上 V 也不存在了,因为 V 就是 K 的前 512 维。
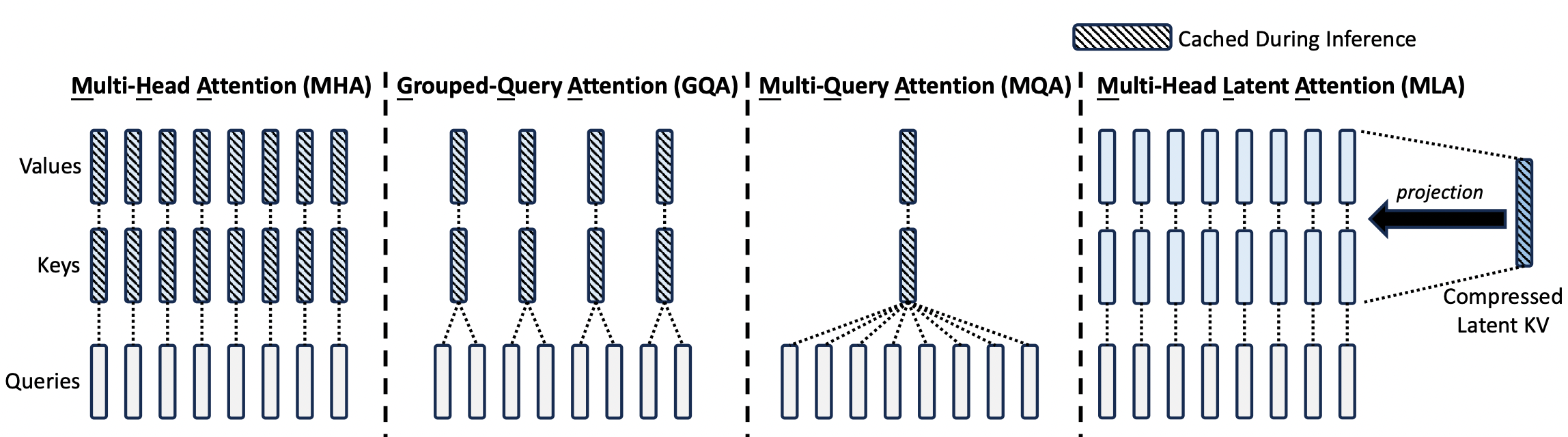
再回看图 1,你会发现,这不就是 MQA 么?而这就是实际上 FlashMLA 代码库解决的问题:提供了一个专门为 q k head dim 为 576,v head dim 为 512,v 与 k 的前 512 维重叠,q head 数不超过 128(TP 下会变少)设计,仅支持 H800/H100 GPU 的 MQA 优化算子。