前一篇博客《使 SGLang 支持在 32 张 L40S 上运行 DeepSeek-R1》中提到我那非常特殊的 L40S 显卡配置,结果发现是个大乌龙。
首先,这台机器有 PCIE 4.0 Switch,每张 Switch 上插了 4 张 L40S 显卡。我误会的 PCI-to-PCI 应该是挂了一个给监控屏用的小显卡。
其次,有一张网卡插错位置了。本来应该每 4 张显卡配 1 张双口网卡,其中一张没插到对应的 Switch 上。
最后,3 张网卡 6 个网口,只启用了 1 个网口,有 5 个网口没启用。
所以,实际上所有机内通信走的都是 PCIE,所有跨机通信走的都是主网卡,这……只能怪自己没经验,默认以为交过来的环境都是对的。
折腾了几天,总算搞对了,正确的拓扑如下:
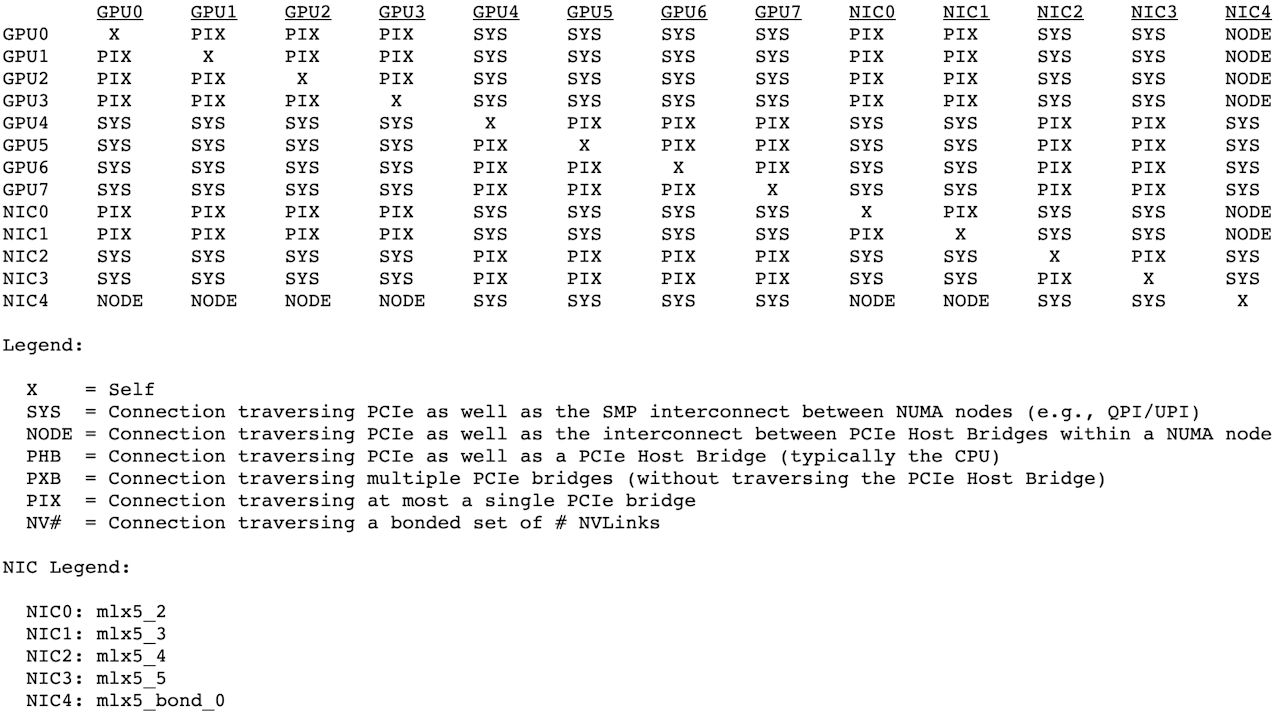
主网卡两个网口做了链路聚合,用作 TCP 通信;PCIE Switch 上的 4 个网口专用作 RDMA 通信。同机两个 NUMA 域双卡之间通信,走 PCIE 大概 11GB/s,走 GDRDMA 能提升到 19GB/s。最关键的是多机通信,从单网口的小水管提升到了 4 网口 GDRDMA。
采用与上篇文章同样不严谨的测试方式:
# 128 并发
[TP0] Decode batch. #running-req: 128, #token: 86816, token usage: 0.44, gen throughput (token/s): 777.92, #queue-req: 0, # 之前 565.73, 1.37x
# 32 并发
[TP0] Decode batch. #running-req: 32, #token: 8923, token usage: 0.04, gen throughput (token/s): 457.66, #queue-req: 0, # 之前 260.73,1.75x
# 4 并发
[TP0] Decode batch. #running-req: 4, #token: 1437, token usage: 0.01, gen throughput (token/s): 153.98, #queue-req: 0, # 之前 42.3,3.64x
# 1 并发
[TP0] Decode batch. #running-req: 1, #token: 482, token usage: 0.00, gen throughput (token/s): 49.02, #queue-req: 0, # 之前 26,1.88x
固定 200 输入,200 输出,128 并发,2 轮请求:
============ Serving Benchmark Result ============
Backend: sglang-oai
Traffic request rate: 128.0
Max reqeuest concurrency: 128
Successful requests: 256
Benchmark duration (s): 87.57
Total input tokens: 51200
Total generated tokens: 51200
Total generated tokens (retokenized): 51023
Request throughput (req/s): 2.92
Input token throughput (tok/s): 584.64
Output token throughput (tok/s): 584.64 # 之前 391.47,1.49x
Total token throughput (tok/s): 1169.28
Concurrency: 127.23
----------------End-to-End Latency----------------
Mean E2E Latency (ms): 43524.37
Median E2E Latency (ms): 43246.71
---------------Time to First Token----------------
Mean TTFT (ms): 7225.06
Median TTFT (ms): 6769.52
P99 TTFT (ms): 14229.37
---------------Inter-Token Latency----------------
Mean ITL (ms): 182.87
Median ITL (ms): 162.95
P95 ITL (ms): 166.60
P99 ITL (ms): 202.39
Max ITL (ms): 13711.39
==================================================
可以看到,修复网络本身存在的问题以后,推理性能提升还是很显著的。
one more thing
前一篇文章提到: L40S/L20 虽然支持 FP8 精度,却不能运行 FP8 的 DeepSeek-V3/R1。这个问题搞定了,我已经实现在 L40S 上运行原始 FP8 参数的 DeepSeek-R1,满血+纯血。等我整理一下代码,下篇博客来介绍一下。