昨天睡前看到一个知乎问题 “DeepSeekV3.1 提到的 UE8M0 FP8 Scale 是什么?有什么妙用?[1]” 正好我最近读了一些有关的代码,就写了个回答[2]。
博客里再展开说一下。
这个早,有多早呢?其实也不是很早。Nvidia 的同学在今年 6 月 12 日给 DeepGEMM 提交了一个 PR “DeepGEMM#112 Add more GPU architectures support[3]”,添加了对 SM100 ( Blackwell) 的支持;但是 DeepSeek 的同学说我们没 SM100 的卡,没法测;SGLang 的同学看到了,说我来验证下。最终,这个 PR 在 7 月 18 日合入了 DeepGEMM 主干。
但是 SGLang 和 vLLM 的集成,在早于 7 月 18 日就开始了。比如 SGLang 在 6 月 14 日合入了 “sglang#7156 Re-quantize DeepSeek model weights to support DeepGEMM new input format[4]”, “sglang#7172 Support new DeepGEMM[5]” 等;vLLM 在 6 月 25 日就 accidentaly 合入了 “vllm#19280 [Feature] Integrate new deepgemm[6]”。
从这个过程可以看到,DeepGEMM 推理上用的 UE8M0,还是 Nvidia 家实现的 MXFP8,跟训练时的国产卡用的 UE8M0,可能是两件事。
Nvidia 家在 Blackwell 的第 5 代 TensorCore 设计中引入了 mxf8f6f4 指令族,这个指令族的含义是:在进行 FP8、FP6、FP4 TensorCore 乘法时,可以同时传入一个 MXFP8 的量化/缩放因子(UE8M0 格式),在执行 TensorCore 后直接输出反量化后的结果矩阵,不需要像以前一样还要调用 CUDA Core 进行 element-wise 反量化。
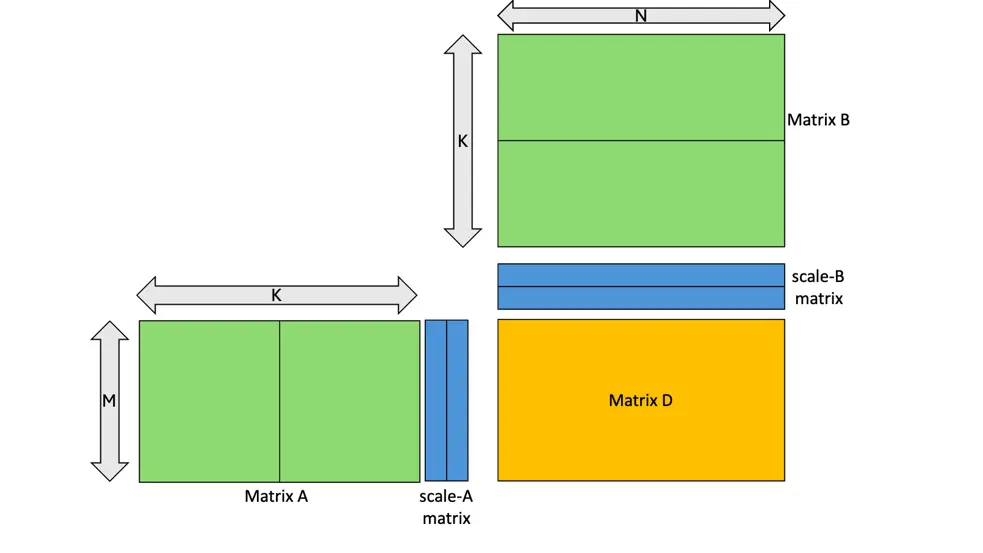
Nvidia 针对 DeepSeek-V3/R1 的 128x128 的 blockwise scaling,为了适配 mxf8f6f4 指令族,将 128x128 共享的一个 fp32 缩放因子 sf,拆成 128x4 个相同的 ue8m0 缩放因子。这样就能实现在每次 TensorCore 调用时,都传入这次 TensorCore 乘法对应的缩放因子。
SGLang/vLLM 推理框架为了适配 DeepGEMM,在 SM100 卡上加载模型的时候,会把 FP8 128x128 的 block 先反量化成 BF16,然后再用 microsoft/microxcaling[8] MXFP8 的思想,但是仍然以 128x128 的大小(而不是 1x32 一个缩放因子),使用 UE8M0 的缩放因子进行 block 量化。这样做的原因,可能主要是 DeepSeek 在训练时原生地使用了 blockwise FP8,如果在训练时原生使用 BF16 的模型,可能直接按照 MXFP8 量化精度更高。
虽然量化时缩放因子仍然是 128x128 block 的,即 NxK 矩阵的缩放因子是 (N/128)x(K/128)。但是送 DeepGEMM 计算前会广播到 N 维,并且将 4 个 uint8 pack 到 int32,也就是说送 DeepGEMM 实际的缩放因子是 N x (K/128/4)。具体的细节可以参考 sglang#7156[4] 或者 sglang.srt.layers.quantization.fp8_utils.requant_weight_ue8m0_inplace 函数的实现。
因为目前这种计算只在 DeepGEMM 实现,所以这种加载模型后的在线重量化,只对 DeepGEMM 生效。比如你如果开了 EP,就会对专家生效;但是你如果全TP,那对专家不生效,只对QKVO、MLP 等生效。
所以推理时量化/缩放的粒度仍然是 128x128 的,但通过广播,最终计算粒度变成了 MXFP8 的。不过,DeepSeek 官方留言:
UE8M0 FP8是针对即将发布的下一代国产芯片设计。
到底是指 MXFP8,或者更新型的一种 FP8 计算,就不得而知了。
- https://www.zhihu.com/question/1941882763503473149
- https://www.zhihu.com/question/1941882763503473149/answer/1942001470040946495
- https://github.com/deepseek-ai/DeepGEMM/pull/112
- https://github.com/sgl-project/sglang/pull/7156
- https://github.com/sgl-project/sglang/pull/7172
- https://github.com/vllm-project/vllm/pull/19820
- https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#tcgen05-mma-block-scaling
- https://github.com/microsoft/microxcaling