随便一本《近世代数》或者《抽象代数》书上在讲到置换群的时候,应该都会讲到这样一个定理:
任何一个置换都可以表示为不相交轮换的乘积,若不计因子的顺序,其分解式是唯一的。
一、简单解释
没有数学背景的人,这句话很难读懂,下面我们来看一个简单的例子。假设我们有这样一个置换 P:
1, 2, 3, 4, 5
2, 5, 4, 3, 1
那么这个置换是什么样的轮换的乘积呢?我们先从 1 出发,1 被换到 2,2 被换到 5,5 又被换到 1,这就是一个轮换;然后再从 3 出发,3 被换到 4,4 又被换到 3,这又是一个轮换。也就是说 P 是两个不相交轮换 (1, 2, 5) 和 (3,4) 的乘积。
二、一个应用:全排列判断问题
下面我们来看这个定理有什么作用,考虑下面这道题目[1][2]:
给一个 n 长的数组,判断它是否为一个 1, 2, ..., n 的全排列,要求在线性时间,常数空间内实现。
我们可以容易看到,每个全排列都可以视为 1, 2, ..., n 上的一个置换。问题就转化为检测该数组是不是一个 1, 2, ..., n 的置换。由本文开头提到的定理可知,我们只需要检查该置换是不是由不相交的轮换构成的即可。
还是上面那个例子,怎么检查
1, 2, 3, 4, 5
2, 5, 4, 3, 1
是不是一个置换呢?首先从 1 开始,a[1]=2,那么再检查 a[a[1]]=a[2]=5,然后再检查a[a[a[1]]]=a[5]=1,这样就发现了一个轮换 (1, 2, 5)。然后接下来检测第二个,第三个轮换...
如何保证检查的高效以及所有轮换都不相交呢?我们每次检查完一个数,就将它置负,这样遇到负值,循环就终止了。如果终止前检查的那个数与起始的数相同,那么我们就发现了一个轮换,否则它就不是一个轮换,说明 P 不是一个置换。由于检查过的轮换中的数字都被置为负值,所以第二个轮换肯定不会与第一个轮换相交。如果到最后所有的数都被置为负值,且循环正常终止,那么说明它们都在不相交的轮换里,那么 P 就是一个置换。
如果想要查找过程不影响最终数组的值,到最后把所有置负的元素都重新置正即可。
代码实现如下[2]:
/* We use a n+1 elements array a[n+1] for convenience. a[0] is used to store
* the return value, thus is not part of the permutation. */
int test_perm(int *a, int n)
{
int i, j;
if (a == NULL) return 0; /* Test input */
a[0] = 1;
for (i = 1; i <= n; ++i) /* Test input */
if (a[i] < 1 || a[i] > n) { /* Is a[i] in the range 1~n? */
a[0] = 0;
return a[0];
}
for (i = 1; i <= n; ++i)
if (a[i] > 0) {
j = i;
while (a[j] > 0) { /* Follow the cycle */
a[j] = -a[j];
j = -a[j];
}
if (j != i) a[0] = 0; /* Test the cycle */
}
for (i = 1; i <= n; ++i)
a[i] = a[i] > 0 ? a[i] : -a[i];
return a[0];
}
三、另一个应用:100 囚徒碰运气问题
那么这个定理还有其它的用处没有呢?考虑下面这道题目[3][4]:
100 个囚犯,每人有一个从 1 到 100 的不重复不遗漏的号码,国王把这些号码收集起来,打乱放进 100 个箱子里,每个箱子里有且仅有一个号码。囚犯们一个一个地来到 100 个箱子面前,每人可以打开至多 50 个箱子来寻找自己的号码,可以一个一个打开(即可以根据之前箱子里看到的号码来决定后面要打开的箱子)。如果有一个囚犯没有找到自己的号码,那么这 100 个人一起被处死;只有当所有的囚犯都找到了自己的号码,他们才会被国王全部释放。
囚犯们可以在没开箱子前商量对策,但是一但打开了箱子,他就不能告诉别人箱子和号码的对应关系。问他们应该用什么样的策略以保证最大的存活概率?
显然,每个人随机选 50 个箱子打开,100 个人的存活概率会是 1/2 的 100 次方,即1/1267650600228229401496703205376,可以小到忽略不计。但是事实上有一种极简单的办法,其存活概率高达 30% 。至于有没有更好的办法?我不知道。
存活率达 30% 的策略就是:
囚犯打开自己号码对应的箱子,就按照箱子中的号码打开另一个箱子,一直到找到自己号码或者选50 次为止,这样就能保证整体有 30% 的存活概率。
这个策略背后的数学原理是什么呢?其实国王所作的事情,就是一个 1 到 100 元素集合的置换,囚犯所做的事情,就是顺着自己号码所在的轮换找自己号码。那么什么时候所有人都不用死呢?就是这个置换中所有的轮换长度都不大于 50,因为每个囚犯号码的轮换都不大于 50,那么他总能在 50 次以内找到自己的号码。
怎么计算这个概率 P 呢?{这个置换中所有的轮换长度都不大于 50 的概率},就是 1 - {存在轮换长度大于 50 的概率},进而 1 - {存在轮换长度为 51, 52, ..., 100 的概率},由此,我们可以得到下面的等式:
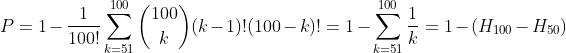
其中,Hn 代表调和数(Harmonic Number)。虽然调和数没有精确的公式,但是我们知道调和数和自然对数有着密切的联系[5],那么我们就可以用自然对数来近似:
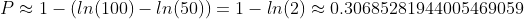 [6]
[6]
因此,我们可以得到,使用这种策略 100个囚犯的存活概率 P 约为 30%。
[1] http://yueweitang.org/bbs/topic/22
[2] http://fayaa.com/tiku/view/84/
[3] http://tydsh.spaces.live.com/Blog/cns!435F1A315756AD5D!833.entry
[4] http://fayaa.com/tiku/view/141/
[5] http://en.wikipedia.org/wiki/Harmonic_number#Calculation
[6] 求和得到的更精确的结果是:0.31182782068980479698,Bash 代码:
STR="1-("
for i in `seq 51 99`; do
STR+="1/$i+"
done
STR+="1/100)"
echo $STR | bc -l