一个东西从 idea 到实现,中间有着巨大的鸿沟,DeepSeek-V3 的 Multi-Token Prediction 也一样。虽然开源社区很多在一个多月前已经支持了基于 TP 的 DeepSeek-V3 推理,但是 MTP 部分目前都还在开发中,进展最快的可能是 vLLM,参见 vLLM PR #12755 [5] 。
但我觉得这并不是一个终点,可能还有很多工程优化工作需要继续完成。下面我尽量用浅显的图表和语言来说明我的理解和思考,如有错误也欢迎指出。
Speculative Decoding (投机解码)
理解 MTP 首先要理解 Speculative Decoding,这里不过多介绍,仅用一张图说明 Speculative Decoding 的计算过程,便于理解后续的分析。如果希望深入了解可以观看 这个 Youtube 视频 [1]。
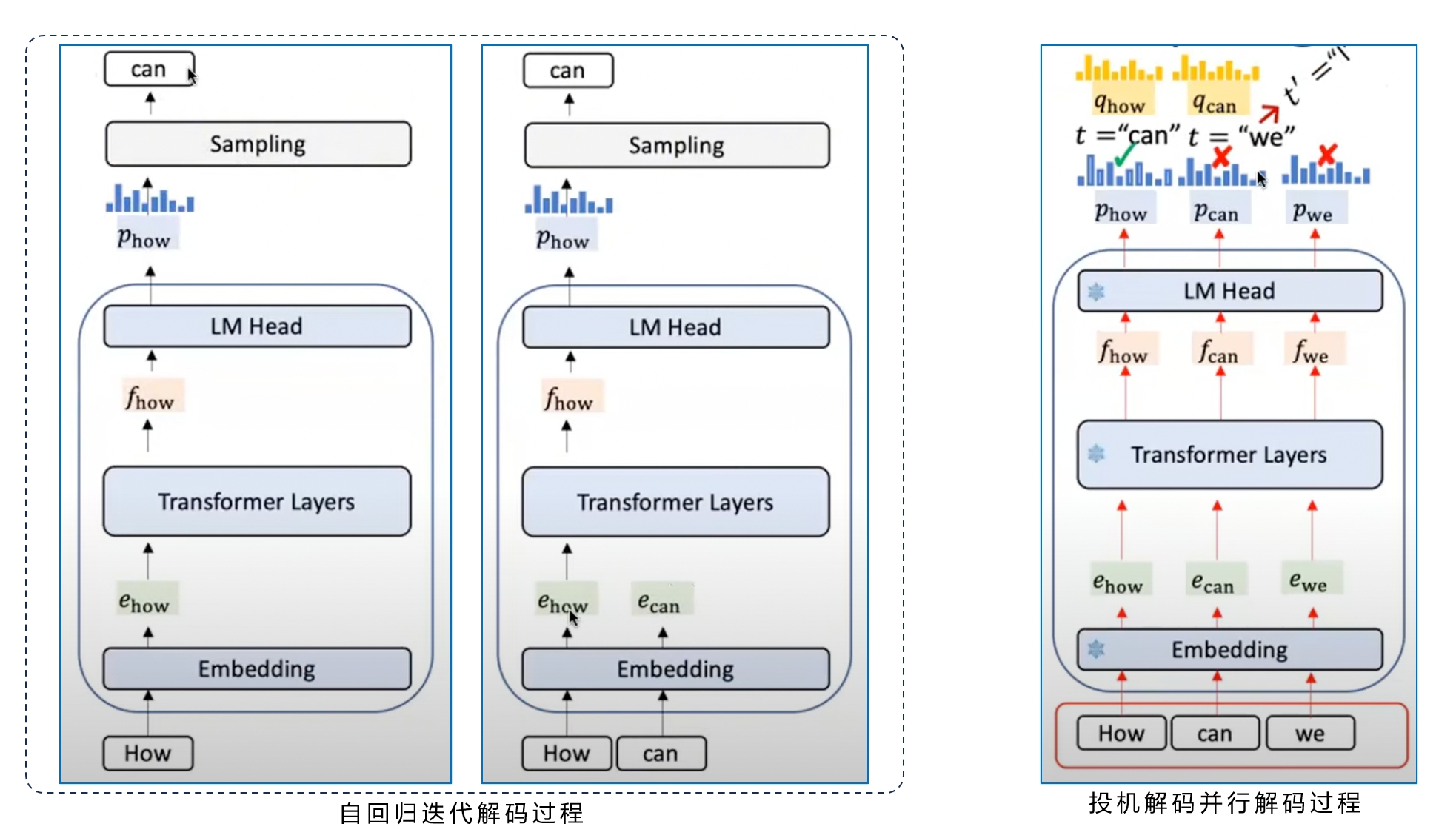
左边展示的是常规的 LLM 自回归迭代计算过程。
初始 prompt 是 token: "how",how 先经过 embedding 计算变成 ehow,然后经过 Decoder Layer 的计算,输出特征向量 fhow(最后一层 hidden states),经过 LM Head 转换成一个概率分布向量 phow,通过采样得到生成结果 token:"can"。
然后 LLM 会把 can 作为新的输入,进行下一步的计算,直到 LLM 给出推理结束 token:"<EOS>"。
自回归解码是逐 token 迭代进行的,生成一个 token,将 token 作为输入生成新的 token,直到遇到结束条件:生成 "<EOS>" 或者达到最大生成长度。
右边展示的是 Speculative Decoding 的过程。
初始 prompt 还是 how,但是通过其它方式(比如一个小模型,叫做草稿模型)先推测了两个草稿 token:"can、we",同时输入到目标模型。普通的 Decoder 实现仅能解码 1 个 token,这里改造成能够同时解码输出 3 个 token 的 hidden states。这样我们就能同时得到:phow, pcan 和 pwe。然后就可以跟草稿模型输出的 qhow 和 qcan 进行比较,验证是否接受草稿模型的草稿 token:can 和 we。
图上目标模型验证结果是接受 can,但是拒绝 we,那就使用 pcan 采样,得到生成结果 token:I。这就意味着,投机解码通过一次推理,得到了两个 token:can、I,实现了1倍逻辑加速:can 是推测以后得到验证的 token,I 是拒绝推测 we 以后,根据目标模型自身输出采样的 token。
EAGLE 与 DeepSeek-V3 MTP
EAGLE 简单说来是作者认为通过目标模型本身的特征向量(就是上面的 fhow)预测下一个 token 更准确,所以草稿模型使用了与目标模型基本相同的结构,利用了目标模型输出的特征向量(fhow)作为草稿模型输入。如果希望深入了解可以观看 这个 Youtube 视频 [1]。
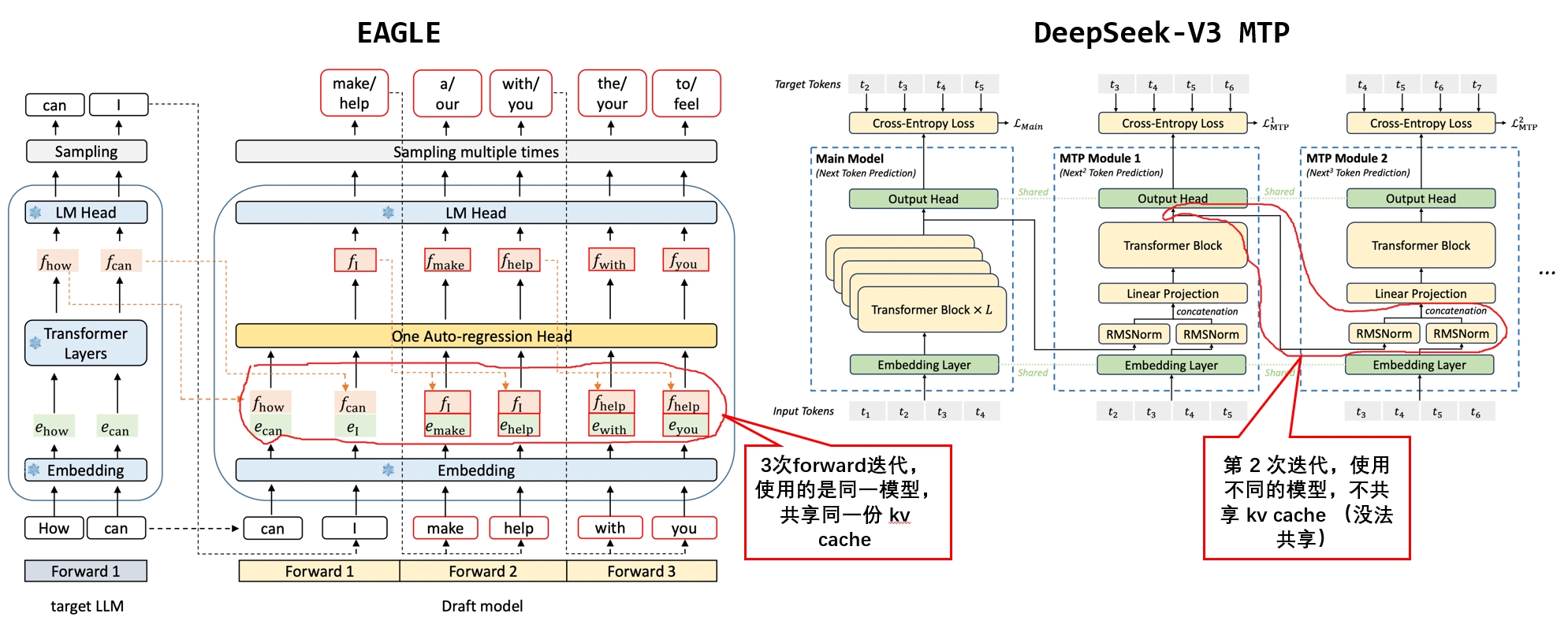
MTP 与 EAGLE 不同的点如上图所示,除了多做了一次 Norm 这种细节之外,主要是多步推理的时候的串行。EAGLE 在多步推理时,只使用到了一个草稿模型做自回归推理;MTP 在多步推理时,其实是多个草稿模型进行串行推理。
了解完上面这些背景以后,我们可以分析如果希望实现 DeepSeek-V3 MTP,都需要做哪些工作。
MTP 实现
1. MTP 加载
虽然很多框架都支持了 EAGLE,但一般的实现,都只支持 1 个草稿模型。而 MTP 从设计上,需要加载多个草稿模型,每一个 MTP 层,都是一个草稿模型。
在推理的时候,要根据不同的 step,选不同的模型进行推理。这就使得 MTP 草稿模型的加载和推理的调度比其它投机编码要复杂。
但如果 MTP 的步长等于 1,那就相当于 1 个草稿模型,实现会简单很多。
2. MTP Prefill
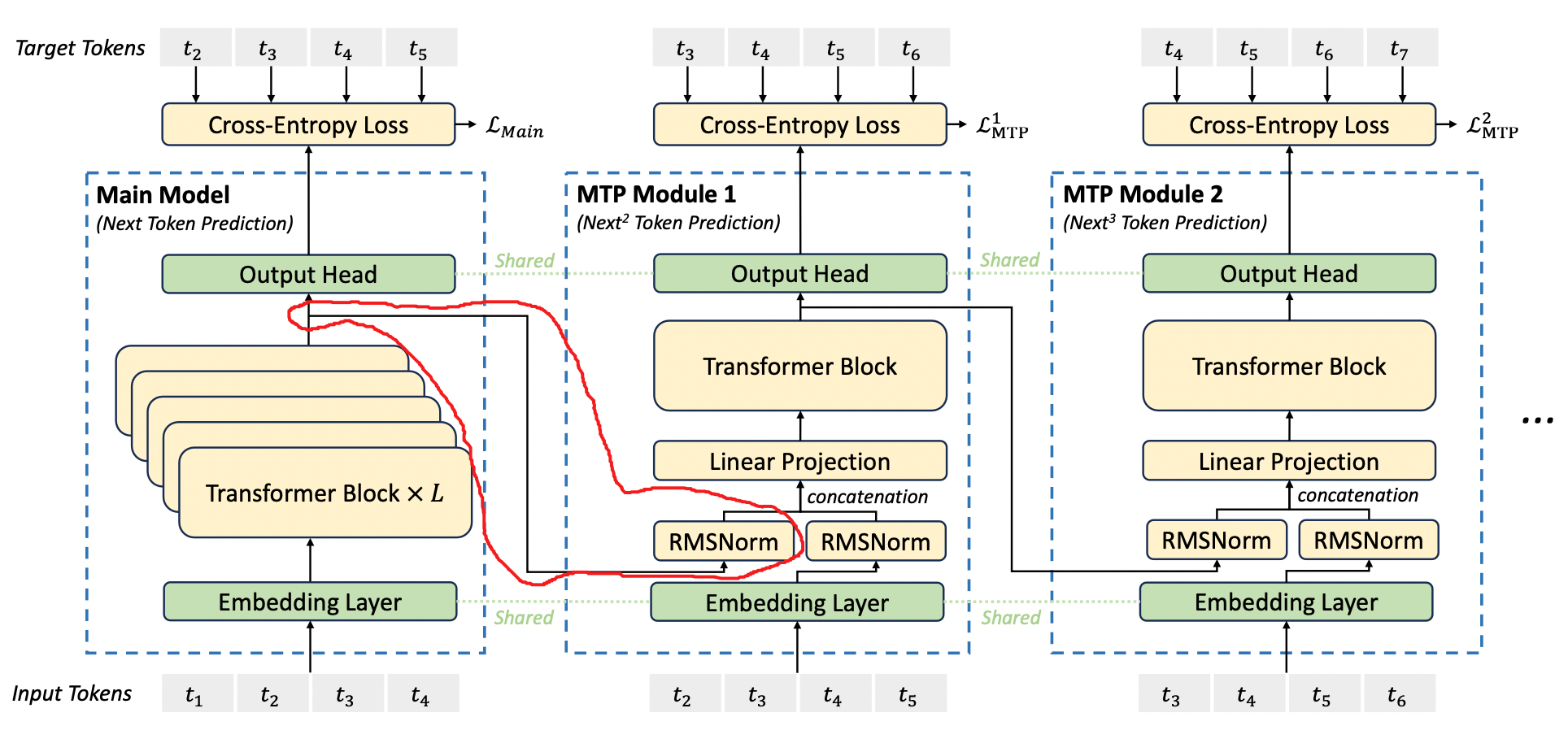
从上图可以看出,第 i 个 MTP Module 的输入 token,是第 i+1 个 token 到第 n 个 token,n 是当前生成的总长度。而它不仅需要 token 的 embedding,还需要 token 在前一个模型计算得到的 hidden states。
比如 MTP Module 1 的输入,是 token 2 到 5 的 embedding 和 main model 最后一层输出的 token 2 到 5 的 hidden states。
这也就意味着,在完成 DeepSeek-V3 的 prefill 时,需要输出最后一层的 hidden states,才能进行第 1 个 MTP 的 prefill;第一个 MTP 输出最后一层的 hidden states,才能进行第 2 个 MTP 的 prefill,以此类推。
可以注意到:多个 MTP 的多次 prefill 计算是串行的。这意味着每增加 1 个 MTP Module,每次推理的时候就要多一轮串行的 prefill,并且多一份 kv cache。一个主模型加 N 个小模型的推理,可能会严重影响计算调度的效率,可能这也是为什么 DeepSeek-V3 只输出了 1 个 MTP Module 的原因。大概他们也认为,仅使用 1 个 MTP Module 性价比最高。
3.MTP PD 分离
我在之前一篇博客[4]中列举了 PD 分离背后面临的很多架构选择,MTP 会让 PD 分离变得更复杂。框架有两种选择:
选择一:Prefill 节点做 MTP Prefill:如下图所示,P 节点做完 DeepSeek-V3 Prefill 以后,保留最后一层所有 token(除了第 1 个,即index 0)的 hidden states,采样生成的第一个 token,获得 tokenid,然后将这些输入到 MTP Module 1 做 Prefill。最后将 1) DeepSeek-V3 61 层的 KV Cache; 2) DeepSeek-V3 MTP 的 KV Cache; 3) DeepSeek-V3 生成的第一个 tokenid;4) DeepSeek-V3 MTP 生成的第一个草稿 tokenid 和概率;这 4 部分传给 D 节点。
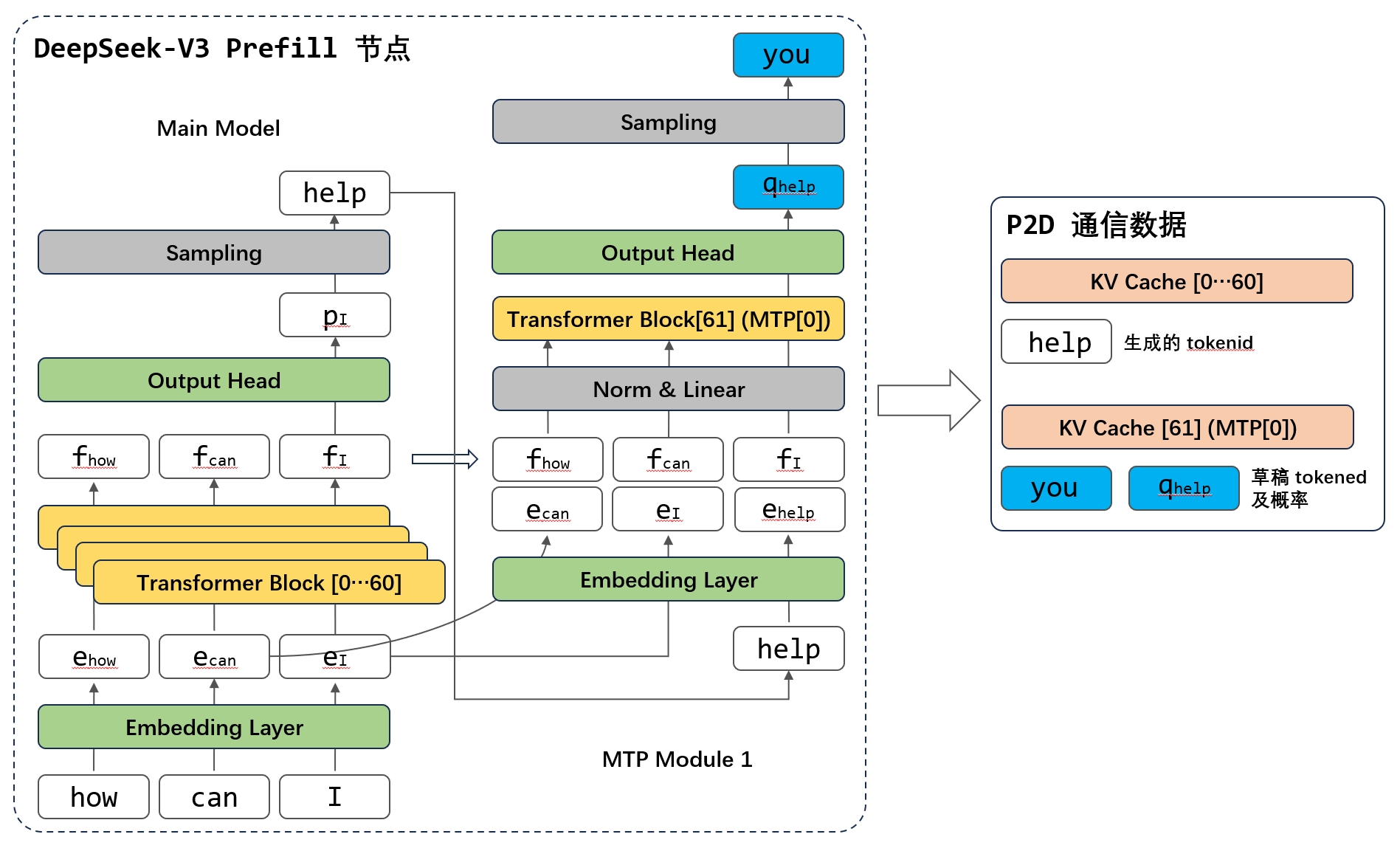
选择二:Prefill 节点不做 MTP Prefill:P 节点做完 DeepSeek-V3 Prefill 以后,把:1) DeepSeek-V3 61 层的 KV Cache; 2) 最后一层所有 token(除了第 1 个,即index 0)的 hidden states;3)所有 token (除了第 1 个,即 index 0)的 embedding。这 3 部分传给 D 节点。D 节点将生成第一个 token 的 hidden states 经过 LM Head 计算和采样获得 tokenid,然后对 MTP 进行 Prefill。
考虑到通信量和复杂度,大概大家都会选择一,但这样 Prefill 节点就必须加载 LM Head 了,因为 MTP 依赖生成的 tokenid 做 embedding 输入。
4. MTP MLA 算子优化
由于 MLA 的复杂性,现在的很多 MLA 实现并不支持在 decode 单次前向计算时同时并行计算多个 Query token,所以只能通过 Batch Expansion 进行投机解码。
Batch Expansion
以 how [can, we] 举例,我们可以展开成 3 个请求:
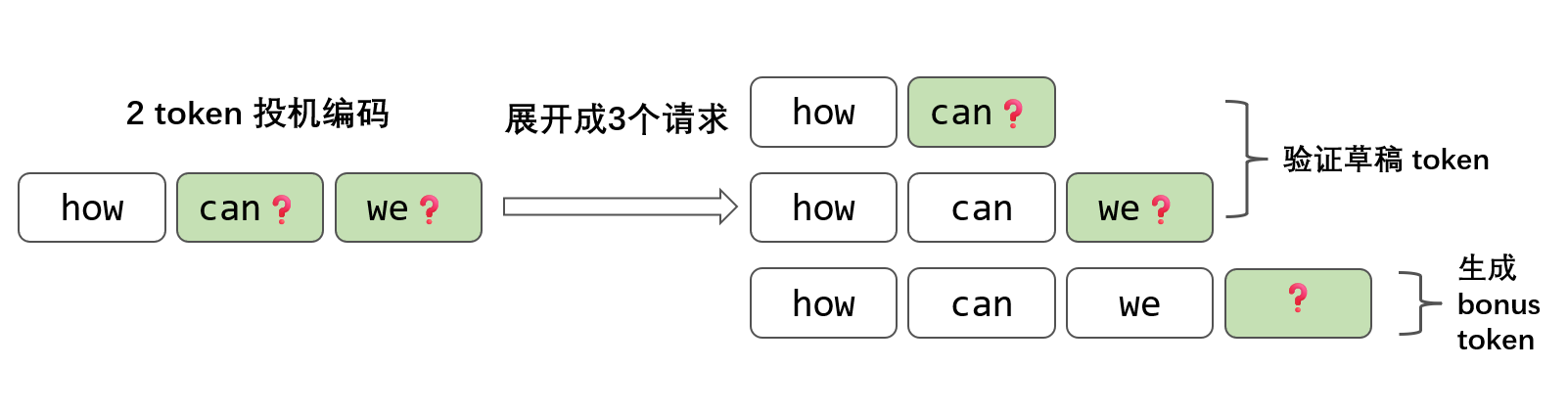
从逻辑上来看,请求变多了,但 3 个请求放到一个 batch 中可以进行并行计算,可以共享 prefix cache (如果先做 prefill 的话),这样我们依然可以拿到 phow, pcan 和 pwe。通过并行请求也能够实现 1 次 Decode 验证多个 token。
这里要注意一个逻辑:虽然要验证 2 个 token,但是却展开成了 3 个请求。这样如果全部两个草稿模型投机推理的 token 都被接受了,那第 3 个 token 会由目标模型自己生成,这个 token 被称为 bonus token。
虽然 Batch Expansion 能解决投机编码时的并行问题,但 Batch Expansion 有一定的计算开销。在高吞吐的时候,会抵消投机编码带来的加速。更好的优化就需要 MLA 算子在单次前向计算时,同时 decode 2 个 query token,这有一定的改造成本。
5. MTP 并行和 overlap 优化
以 DeepSeek-V3 的参数规模,模型并行必不可少。尤其是考虑到微批计算、通信的 overlap 带来的高效率,MTP 的推理未必能像一般的草稿模型一样,单独执行。
很有可能需要将 MTP 的推理和 Speculative Decoding 的打分、验证融入到 DeepSeek-V3 模型中。通过一次前向计算,完成:1) 草稿 token 的打分和验证;2) 生成 token 的输出;3) 新草稿 token 的生成。类似于图 4,我就不画了。
结语
所以个人思考,DeepSeek-V3 MTP 的最优实现方式,很大可能是将 1 层与主模型融合在一起调度,而不是按照独立模型单独执行;在 PD 分离时由 Prefill 节点同时负责 MTP 的 prefill。
[1] EAGLE and EAGLE-2: Lossless Inference Acceleration for LLMs - Hongyang Zhang, https://www.youtube.com/watch?v=oXRSorx-Llg
[2] EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty, https://arxiv.org/abs/2401.15077
[3] DeepSeek-V3 Technical Report, https://arxiv.org/abs/2412.19437v1
[4] LLM PD 分离背后的架构问题, https://yangwenbo.com/articles/reflections-on-prefilling-decoding-disaggregation-architecture.html
[5] https://github.com/vllm-project/vllm/pull/12755