使用 GPU 多机多卡分布式推理和训练时,往往会使用 NCCL 进行卡间通信。一般云上的 GPU 环境,或者有 PaaS 管理的机群,这些都会被妥善配置。但碰巧我有一些物理机,需要自己配置,踩过一些坑,备忘一下便于以后查找。
PaaS 注入的环境变量
PaaS 往往会通过 container 直接注入一些 NCCL 环境变量到容器的 1 号进程,通过 1 号进程启动的子进程会继承这个变量,但是在 shell 中无法直接通过 echo 拿到。
可以在容器内,通过下面这个命令查看所有注入的 NCCL 环境变量:
# cat /proc/1/environ | tr '\0' '\n' | grep NCCL_
NCCL_VERSION=2.21.5
NCCL_DEBUG=INFO
NCCL_SOCKET_IFNAME=bond0
NCCL_IB_HCA=mlx5_8,mlx5_6,mlx5_4,mlx5_0,mlx5_9,mlx5_7,mlx5_5,mlx5_3
NCCL_IB_GID_INDEX=3
...
NCCL_DEBUG
这个环境变量会控制 NCCL 调试日志的打印级别,一般调试时设置到 INFO。在 INFO 级别看不懂的错误,调到更低的 TRACE 级别大概率也是看不懂。
NCCL_IB_HCA 和 NCCL_SOCKET_IFNAME
这里还需要有一点背景知识,RDMA/IB 网络和普通的以太网络有两套不同的术语:
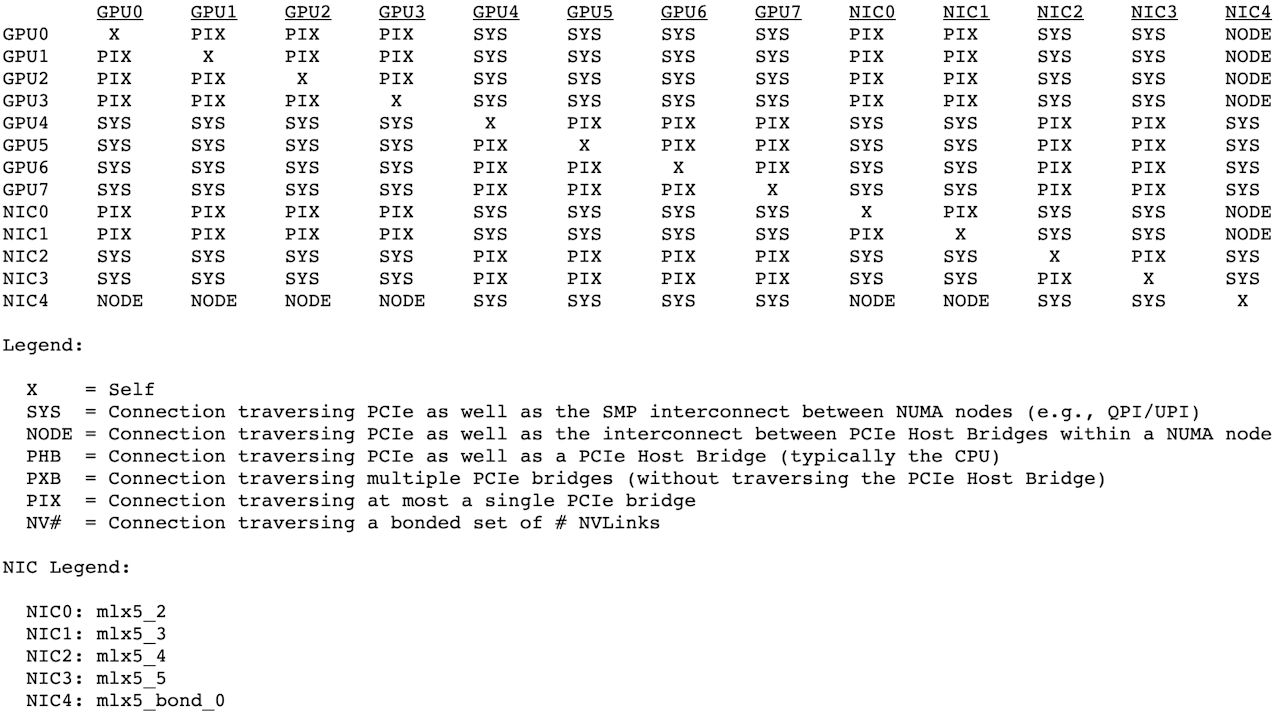
- RDMA/IB 的网络适配器叫做 HCA (Host Channel Adapter),如果用的是 Mellanox 家网卡的话,一般 HCA 名字(HCA ID)类似于 mlx5_*。可以通过 ibv_devinfo/nvidia-smi topo -m 命令列出所有的 RDMA 网络接口。
- 以太网的网络适配器一般叫做 Network Interface 或 IP Interface。一般网卡名是 eth*, ens*, xgbe*, bond*,可以通过 ifconfig 或者 ip addr show 列出所有以太网接口。
在 RoCE 网络下,每个网络接口都有一个以太网接口名和一个 RDMA 接口名(HCA ID)。比如以太网接口 bond0,RDMA 接口 mlx5_bond_0;以太网接口 xgbe2,RDMA 接口 mlx5_2。可以通过下面的方式查询 RDMA 接口对应的以太网接口名:
$ ibdev2netdev
mlx5_2 port 1 ==> xgbe2 (Up)
mlx5_3 port 1 ==> xgbe3 (Up)
mlx5_4 port 1 ==> xgbe4 (Up)
mlx5_5 port 1 ==> xgbe5 (Up)
mlx5_bond_0 port 1 ==> bond0 (Up)
$ cat /sys/class/infiniband/mlx5_2/ports/1/gid_attrs/ndevs/0
xgbe2
背景介绍完毕,下面为了方便,对网卡接口的 IP 就是混着写了。我在单机多卡之间启用 NCCL 通信时,遇到过下面这个问题:
120858:120906 [6] ibvwrap.c:262 NCCL WARN Call to ibv_modify_qp failed with 110 Connection timed out, on dev mlx5_4:1, curr state INIT, next state RTR, local GID index 3, local GID ::ffff:【MLX5_4 IP】, remote GID ::ffff:【BOND0 IP】
从报错来看是两个 RDMA 接口之间建立 RDMA 连接的时候超时。仔细看两个 IP 不在一个网段,一个是机器主网卡(链路聚合网卡)的 IP,一个是仅用做 RDMA 通信的网卡的 IP。可以通过下面的命令验证一下两个 RDMA 接口之间的 RDMA 连接是否连通:
# 在主网卡 RDMA 接口启动 RDMA 服务端
ib_write_bw -d mlx5_bond_0
# 从 RDMA 接口 mlx5_4 请求服务端
ib_write_bw -d mlx5_4 【主网卡IP】
在主网卡和 RDMA 专用的网卡之间不连通,应该是一个正常现象,这可能是因为他们连接的交换机等网络设备配置不同导致的。这时候就需要配置 NCCL_IB_HCA 和 NCCL_SOCKET_IFNAME 来保证 NCCL 能识别这一点。
多说一句:有时候在 paper 里,主网卡可能会叫做 Storage NIC,因为主要跟存储设置通信,也会启用 RDMA,叫做存储网络平面;专用 GPU 通信的网卡一般叫做 CXn NIC,有的甚至每张卡会连到一个专门的网络平面,比如 DeepSeek V3 的训练环境,有 8 个专门的 GPU 计算网络平面,每个平面之间都是不互通的。所以上面说有些网卡之间 RDMA 不连通可能是期望中的。
一般来说,NCCL_SOCKET_IFNAME 要配置为主网卡的以太网接口名,NCCL_IB_HCA 要配置为专用于 RDMA 网络的接口 HCA ID 白名单列表。比如这样:
export NCCL_IB_HCA=mlx5_2,mlx5_3,mlx5_4,mlx5_5
export NCCL_SOCKET_IFNAME=bond0
也可以使用黑名单的方式,或者自动生成白名单的方式,例如:
export NCCL_IB_HCA=^mlx5_bond_0
export NCCL_IB_HCA=$(ls /sys/class/infiniband | grep -E "mlx5_[0-9]+" | paste -sd,)
单机多卡训练时不一定需要 RDMA 通信,但是明确设置 NCCL_IB_HCA 和 NCCL_SOCKET_IFNAME 这两个环境变量,能避免很多 NCCL 做通信方式决策的问题。
NCCL_IB_GID_INDEX
GID 相当于 RDMA 网络中的 IP 地址,但是每个 RDMA 接口会有多个 GID,用户需要自己手动选择使用每个接口的第几个 GID 进行通信。
RoCE 网络下,一般的 HCA 接口下会有 4 个 GID,使用 ibv_devinfo -v 可以列出来每个 HCA 接口的 GID 列表。形如:
GID[0]: fe80:0000:0000:0000:966d:aeff:fed8:f1dc, RoCE v1
GID[1]: fe80::966d:aeff:fed8:f1dc, RoCE v2
GID[2]: 0000:0000:0000:0000:0000:ffff:0a37:5968, RoCE v1
GID[3]: ::ffff:【IPv4】, RoCE v2
一般来说,只有 3 号 GID,是支持 RoCE 交换机子网间通信的,所以在跨机通信时,大部分 NCCL_IB_GID_INDEX 需要选择 3,否则可能导致多机不连通。在本机多卡间通信时,一般 0、1、2、3 都可以,但是为了方便默认设置成 3 也没什么影响。
Docker 启动命令
如果 container 没有配置注入环境变量,可以在自己启动 Docker 时从命令行注入环境变量,比如:
docker run --network=host -it --runtime=nvidia --gpus all --shm-size=700g --privileged \
--cap-add=SYS_ADMIN --cap-add=NET_RAW --cap-add=NET_ADMIN --cap-add=IPC_LOCK \
--ulimit memlock=-1 --device=/dev/fuse --device=/dev/infiniband \
-e NCCL_IB_HCA=mlx5_2,mlx5_3,mlx5_4,mlx5_5 -e NCCL_SOCKET_IFNAME=bond0 -e NCCL_IB_GID_INDEX=3 \
...
nccl-tests
nccl-tests 是比较便捷的 NCCL 连接测试工具,可以自己编译,但很多 docker 镜像中都会自带这个工具,比如 sglang:dev,用起来更方便。可以通过下面的命令测试单机多卡之间连通和性能(如果卡之间需要 RDMA 连接的话):
NCCL_IB_HCA=^mlx5_bond_0 NCCL_SOCKET_IFNAME=bond0 all_reduce_perf -b 8M -e 256M -f 2 -g 8
也可以通过 CUDA_VISIBLE_DEVICES 选择对哪几张卡进行连通测试,-g 设置卡的数量:
CUDA_VISIBLE_DEVICES=0,4 NCCL_IB_HCA=^mlx5_bond_0 NCCL_SOCKET_IFNAME=bond0 all_reduce_perf -b 8M -e 256M -f 2 -g 2
但如果想跑多机多卡的 all_reduce_perf,就需要用到 openmpi 和支持 MPI 的 all_reduce_perf (可以通过 ldd all_reduce_perf 查看是否依赖 libmpi.so 判断)。openmpi 使用 ssh 登陆多台服务器来分发任务,所以需要在宿主机间,或者容器间配置 ssh 自动登录。下面是一个 2 机 16 卡的 nccl 通信测试命令:
mpirun -np 16 -host IP1:8,IP2:8 -mca btl_tcp_if_exclude lo,docker0 -x NCCL_DEBUG=INFO -x NCCL_IB_HCA=mlx5_2,mlx5_3,mlx5_4,mlx5_5 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_INDEX=3 all_reduce_perf -b 8M -e 256M -f 2 -g 1