读过 DeepSeek V2 Paper 的人可能对下面这张图印象非常深刻,非常直观地揭示了 MLA 算法的基本原理。但结合这张图或者 MLA 公式去看 DeepSeek 在开源周发布的 FlashMLA [1],可能就一脸懵逼了。
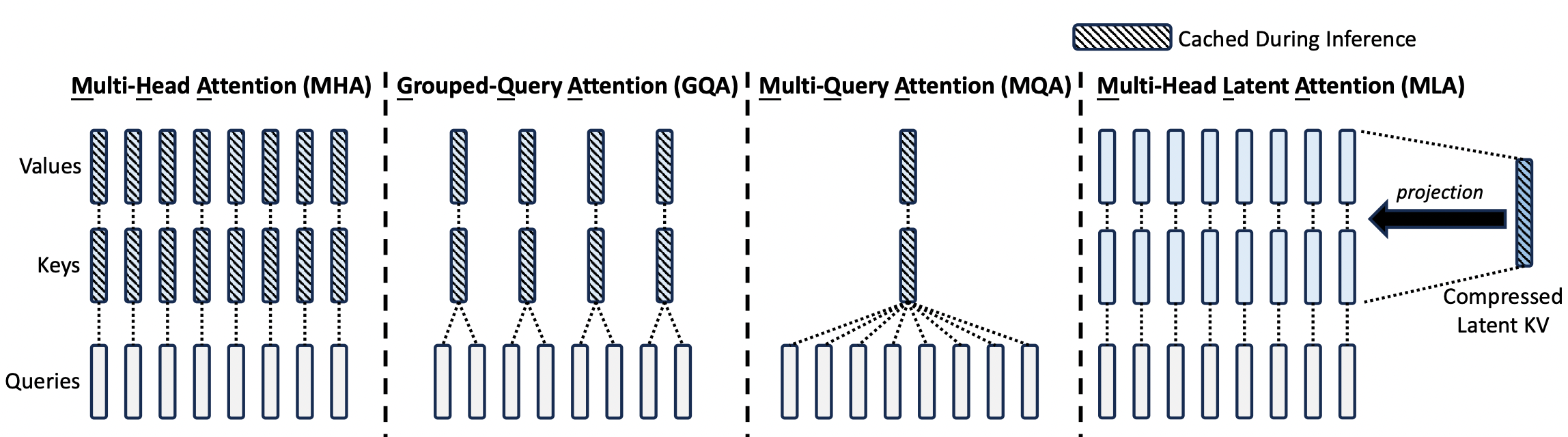
理解 FlashMLA 代码库解决的是怎样一个问题,还需要更进一步的理解 MLA 计算的优化过程。
DeepSeek MLA 公式
下面这张图是 DeepSeek V2 Paper 中的 MLA 公式,相信读到这里的人都知道这是个啥。所以我不做解释,放这里主要是为了方便与下面的图进行交叉阅读。

MLA Naive 实现
最直接的实现 MLA 的方式,就是实现图 2 MLA 的所有计算过程,这个计算过程也与图 1 完全一致。我以 DeepSeek V3 的参数为例,做了下面这张图。
为简化复杂度,这张图里隐藏了两个维度,batch size 和 seq len,或者你可以把它简单地理解成,仅输入一个 token 给模型进行计算的状态。就像我在前面的博客《DeepSeek-V3 MTP 工程实现思考》中做的那样:你仅输入“how”这一个单词给模型,看看模型能给你生成什么。
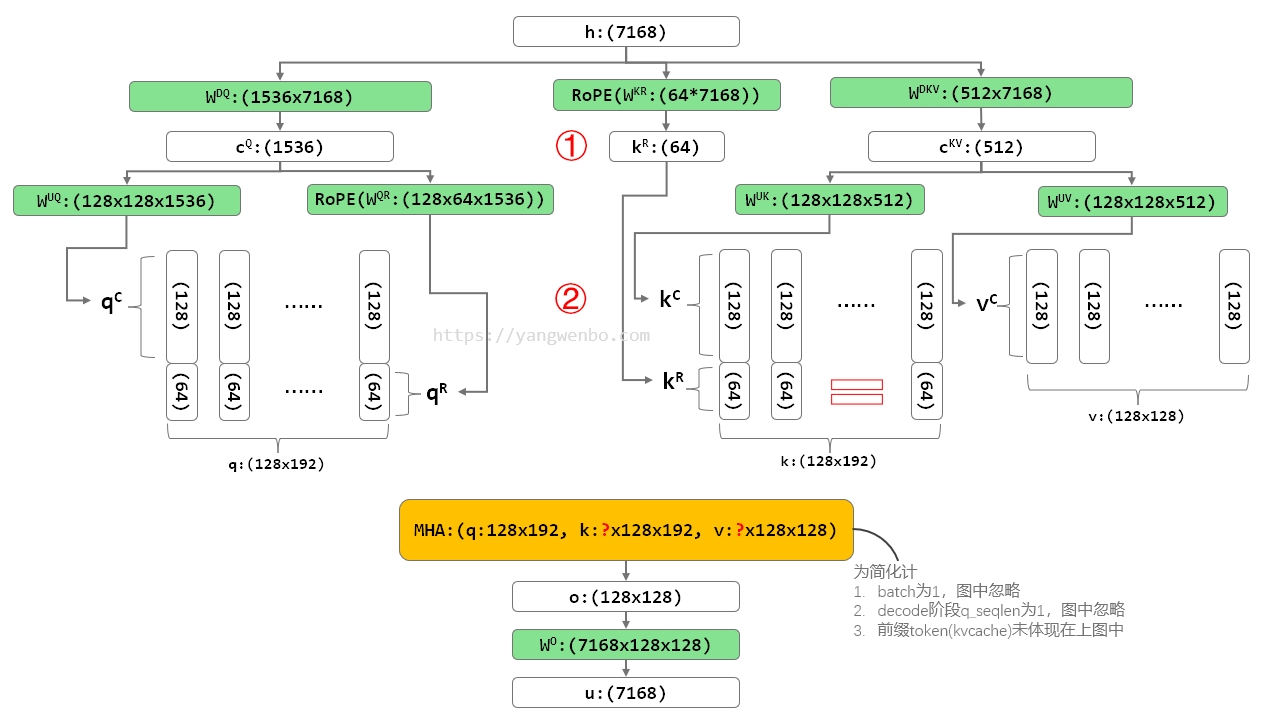
每个绿色的方框代表一次矩阵乘/线性变换,框内是参数矩阵的名字和维度;每个白色的方框代表一个中间结果 tensor,框内是张量名字和维度;黄色的方框则代表核心的 Attention 计算,也就是图 2 中的公式 (46)。参数矩阵和中间结果 tensor 的名字与图 2 保持一致。
在 Naive 实现中,512 维的 Latent KV cKV 被映射回对应 128 个 head,每个 head 128 维的 K kC 和 V vC,然后再拼接上位置向量 kR ,最终形成标准的 q、k、v,输入到标准的 Multi Head Attention 进行 Attetion 计算。与其他常见模型中 MHA 的唯一不同,可能是 head dim 192 不是 2 的 n 次方。
Naive 实现最直观,但它的问题是在 Decode 计算时性能不够好。Decode 计算时,输入的 Q 往往只有一个 token,但需要用到所有前缀 token 的 k 和 v,也就是我们通常说的 KV Cache。Naive 实现有两种选择:
① 缓存 Latent KV。缓存规模小,但 Latent KV 缓存不能直接送 MHA 计算,还得经过 WUK 和 WUV 的线性映射,可以看到这是两个规模不小的矩阵计算,而且每轮都得重复计算。
② 缓存 KV。缓存规模大,不用重复计算,性能好。但 MLA 的一大好处就是 KV Cache 压缩,这样显存内能缓存更多 token,支持更大的 batch 和 prefix cache。如果缓存 KV,在显存上对比 MHA 就完全没有优势了。
所以,Naive 实现可能会用于 Prefill,但在 Decode 计算时需要更好的计算方法。
MLA 优化实现
很多人把下面这种 MLA 的优化称为矩阵吸收[3],来源是 DeepSeek V2 里面这样说:
Fortunately, due to the associative law of matrix multiplication, we can absorb WUK into WUQ, and WUV into WO. Therefore, we do not need to compute keys and values out for each query. Through this optimization, we avoid the computational overhead for recomputing kCt and vCt during inference.
但我更喜欢把它理解成矩阵乘法交换律。因为实际上大家发现,提前将两个参数矩阵乘起来,即把 (WUQ)TWUK 的计算结果做为新的参数矩阵,在性能上还不如分开计算[3]。既然实际计算过程是交换矩阵计算过程,从“矩阵吸收”角度思考反而更绕了。
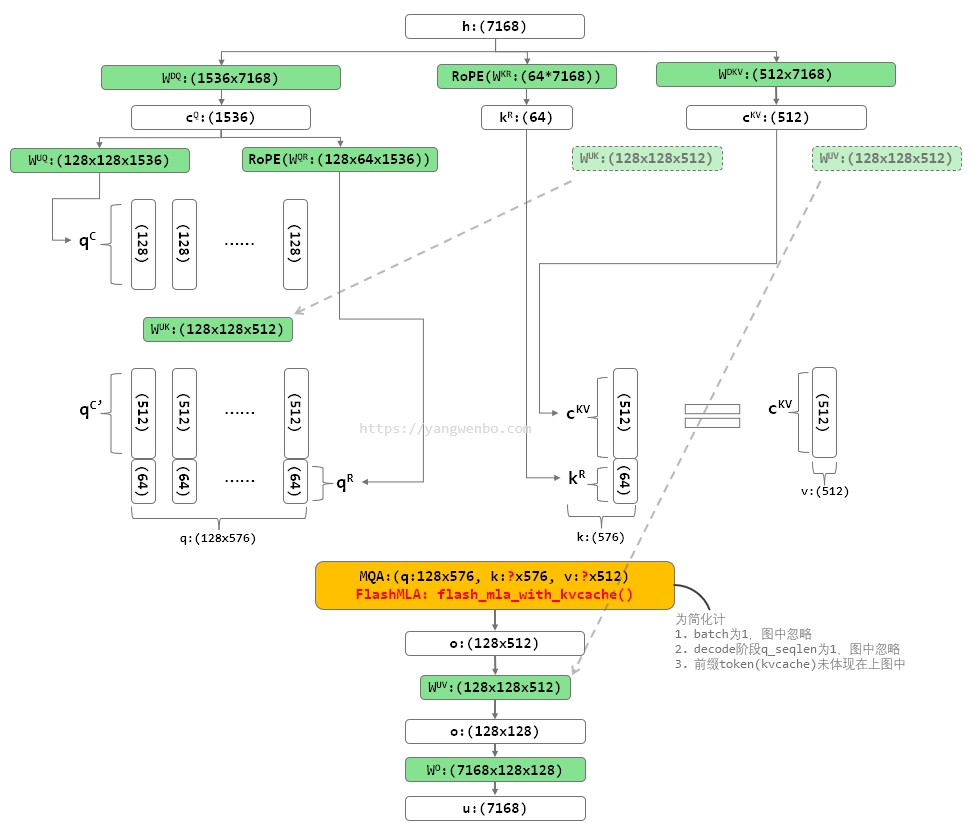
上图中的两个虚线箭头,显示了在优化的计算过程中,哪些参数矩阵被交换了位置。它们能交换的原因,就是从数学上这样修改是等价的(矩阵乘法交换律)。
与图 3 相比,可以看到输入给 Attention 的 q、k、v 形状发生了明显的变化。q 的形状由 128x192 变化成了 128x576,k 的形状由 128x192 变化成了 576,v 的形状由 128x128 变化成了 512。这样一来,原来的 ② KV 就不存在了,新的计算过程中只剩下 ① Latent KV 了。而且实际上 V 也不存在了,因为 V 就是 K 的前 512 维。
再回看图 1,你会发现,这不就是 MQA 么?而这就是实际上 FlashMLA 代码库解决的问题:提供了一个专门为 q k head dim 为 576,v head dim 为 512,v 与 k 的前 512 维重叠,q head 数不超过 128(TP 下会变少)设计,仅支持 H800/H100 GPU 的 MQA 优化算子。
简单来说:虽然这个库叫做 FlashMLA,但它提供的 flash_mla_with_kvcache() 是个 MQA 算子,只不过这个 MQA 的输入形状有些特殊。
小知识
为什么会这样呢?因为开源软件约定俗成的 Attention 算子封装,仅仅指图 2 中公式(46)这一行,是不包含前后的线性变换的。开源推理框架允许用户通过配置选择不同的 Attention 算子实现,比如 FlashAttention、FlashInfer、Triton 实现等。
虽然 MLA 算法的核心在前后的线性变换,FlashMLA 算子却不能提供这些变换。这些线性变换只能被实现在模型建模的 modeling 代码的 MLA 模块中,比如 SGLang 代码库 python/sglang/srt/models/deepseek_v2.py 文件中的 DeepseekV2AttentionMLA [4] Module。
引用
[1] https://github.com/deepseek-ai/FlashMLA
[2] DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, https://arxiv.org/pdf/2405.04434v5
[3] DeepSeek-V2 高性能推理 (1):通过矩阵吸收十倍提速 MLA 算子, https://zhuanlan.zhihu.com/p/700214123
[4] https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/models/deepseek_v2.py